書評 プロフェッショナルTLS&PKI 改題第2版 (PR)
はじめに
『プロフェッショナルTLS&PKI改題第2版(原題: Bulletproof TLS and PKI Second Edition)』が出版されました。今回は出版前のレビューには参加していませんが、発売直後にラムダノートさんから献本をいただきました。ありがとうございます(そのためタイトルにPRを入れてます)。原著のサイトでは前バージョンとのDiffが公開されており、今回は翻訳の確認を兼ねて更新部分を重点的に読みました。このエントリーでは、改訂版のアップデート部分がどのようなもので、今後どう学んだらよいかということを中心に書いてみたいと思います。
短いまとめ: HTTPSへの安全意識が高まっている今だからこそ『プロフェッショナルTLS&PKI』を読みましょう。
長文注意!: 書いているうちに非常に長文(1万字以上)になってしまったので、長文が苦手な方は、GPT-4要約(400字)をお読みください。

今は嵐の前の静けさか?
2018年のTLS 1.3の仕様化から5年が経ち、近頃は大規模な脆弱性に対する急な対応がなくなったなと感じています。朝起きてみたら重大な脆弱性が突然公表されて世の中大騒ぎ、慌てて調査してその日のうちにパッチ当て作業をしなければいけなかったり、日本の連休中なのにOSSのCriticalな脆弱性対応が予告され、眠い目をこすりながら夜中にリリースを待ったりする、ということもかなり少なくなりました。最近ではTLS 1.2をレガシーなものに移行するために機能凍結も提案され、TLS 1.3の耐量子暗号への対応も徐々に進められています。
他方、OpenAIが開発しているQ* というプロジェクトが、多くの平文と暗号文を分析して、未知の数学理論を使いAES-192暗号を破った、という噂も流れています。近い将来優れたAGIが現れて、暗号技術が突然危殆化したり、セキュリティプロトコルの深刻な脆弱性が密かに見つかって知らないうちに悪用されたりする、といったこともあるかもしれません。PKI分野では、政府が認めた認証局をブラウザーに登録することを義務付けるかどうかについて、欧州のeIDAS規則の改正案で議論されています。ブラウザベンダー側は大反発していますが、トラストアンカーの管理をめぐる状況は今後大きく変わるかもしれません。
こうした激動の時が来る前に、今こそ落ち着いてネットワークセキュリティについて学ぶ絶好の機会だと私は考えています。
この本の目的と魅力
セキュリティは難しい分野であることは確かですが、それでも完全に知識がないわけにはいきません。ITの分野で働く全ての技術者には、一定のセキュリティスキルが必要とされるでしょう。その複雑さはダニングクルーガー効果の「完全に理解した」と「全くわからない」の間を頻繁に行き来するものです。セキュリティをさらに詳しく理解しようとすればするほど、各分野で深い知識が要求され、簡単には理解できない泥沼に陥りがちです。
この本の特長は、セキュリティという複雑で高度な技術分野の難しい部分を上手く省略し、比較的理解しやすい言葉で説明している点にあります。また、過去30年近くにわたるTLS/PKIの歴史を通じて生じた技術的な課題や問題点を幅広くカバーしていることも、この本の大きな魅力です。内容は完全な初心者向けではないものの、読者は各自のレベルに応じて「完全に理解した」(もしくは「全く分からない」)までこの本によって引き上げてもらえるでしょう。
この本を始めから一貫して読むのも良いですが、読み物中心の第1章が終わったら業務的な必要や興味に応じて特定の章を選び、自分なりの理解を深めていく方が良いのではないかと思います。実際に手を動かしてみてから同じ内容を再読すると、新しい理解と納得感が得られるはずです。そういう意味ではネットワークのセキュリティ対応を行うIT技術者にとって、いつでも参照できるよう常に一冊手元に置いて置くべき書籍だと思います。著者が始めに「本書の目的は、SSL/TLS と PKI について日常の業務で必要となる実用的な知識をすべて網羅することです」と書いてありますが、まさにそのとおりです。
今回のアップデートについて
本の最新版では、2021年までのTLS/PKIの最新動向を取り入れ、内容がTLS 1.3を中心に更新されています。本書は大きく4つのパートに区分されており、各セクションで行われたアップデートについていくつか紹介します。
パート1: 暗号技術、SSL/TLS、PKIについての概説(第1章〜第4章)
このセクションでは、これまでの歴史、通信と暗号技術の基本、TLS 1.3と1.2の概要、そしてPKIの仕組みについて詳しく解説しています。今回の改訂で最も注目すべき更新点は、TLS 1.3の仕組みに焦点を当てた新しい章が加わったことです。
TLS 1.3
以前は翻訳電子版限定で追加されていたTLS 1.3の章が、今回の改訂により第2章として本文に正式に組み込まれました。また、TLS 1.3の標準化が完了したことを受け、他の章もTLS 1.3に準拠するよう全面的に更新されています。
序章にある「本章では TLS 1.3 について高い視座から概説します」との記述通り、この章ではTLS 1.3の機能と仕組みについて理解するための必要な情報が提供されています。前職ではTLS 1.3の仕様を徹底的に学ぶ勉強会を開催していましたが、全てを習得するまでには2年以上もかかり、とても大変でした。その経験から本書のように最初の方で高い視座から理解することがいかに大切かを強く感じています。
この章の内容は、主に以下の3つの大きな項目に分けられます(内容が重複したりまたがっているような部分もあります)。
- TLSプロトコルのデータ構造とフロー(Record プロトコル、Handshake プロトコル、Alert、拡張)
- TLSのセキュリティを実現している仕組み(認証、暗号に関する計算、暗号スイート)
- 0-RTT
この本では、フルハンドシェイクとセッション再接続のプロセスが主に取り上げられており、TLS 1.3の基本的な知識はしっかりとカバーされていると思います。0-RTTに関しては、TLS 1.3の新しい主要機能として特に詳しく解説されていますが、最初は大まかに読む程度で良く、まずはセッション再接続の仕組みを理解することから始めましょう(後ほど私のブログも紹介します)。
この本では拡張について最小限の内容のみを扱っているので、その点には注意が必要です。著者は、「TLS に対する俯瞰的な理解にとって拡張の中身を詳しく知ることはあまり意味がない」と述べています。確かに拡張は複雑で種類が多く、TLS 1.2から引き継がれたものと新しいものが混在しており、全体的な理解には必ずしも必要ではありません。ただし、後ほど説明するように、TLS 1.3はミドルボックスに対応するために、多くの機能を拡張に押し込んでいます。そのため、TLS 1.3の本質を理解するためには、拡張を通じて実現されている重要な機能について学ぶことが避けられません。TLS 1.3についてもっと深く学ぶ方法については、後ほど詳しく説明します。
公開鍵基盤(PKI)
この章で特に注目すべきアップデートは、CT(Certificate Transparency)とCAA(Certification Authority Authorization)という2つの記述が新たに加わったことです。
CT(証明書の透明性)
CTは、認証局の問題に対応するためGoogleが開発したシステムで、パブリック証明書の透明性を高めることを目的としています。現在、AppleやMicrosoftもこのシステムに参加しており、PKIの標準的な一部として取り入れられています。本書では、CTの必要性や仕組み・現状について技術的な難しい部分には深入りせず、幅広く端的にまとめて概説しています。
現状、CTのシステムに対する監査体制の不足や大規模な運用に伴う可用性確保の困難はあるものの、認証局によるパブリック証明書の発行が公に監視されるようになった結果、一定の効果が得られています。例えば、後の章で触れられているように、Symantecが不正にテスト証明書を発行していた事実が明らかになるなど、CTによる透明性の向上が実際に問題を明るみに出しています。
CTのシステムは、認証局やブラウザベンダーのエンジニアでなければ、一般のIT技術者が直接関わることは少ないかもしれません(*1)。しかし、認証局がネットワークセキュリティの根本としてのトラストアンカーを担っているため、技術者としては現行のPKIシステムがどれほど信頼性を保証しているのかを理解しておくことが重要です。
この節を読むと、翻訳の難しさがよくわかります。特に「ログに登録されているという証明が証明書にない」という部分です。原文では"proof of registration"と"certificate"という、どちらも日本語での「証明」ですが、「証明が証明書にない」となると少しわかりづらくなってしまいます。この場合の "proof"を「証拠」としたならどうかなと最初思いましたが、なかなかピッタリくる日本語が見つからないですね(既にラムダノートさんにフィードバックしています)。読む際には、どのような証明を指しているのかを常に意識しながら進めると良いでしょう。
(*1) 2024年1月5日19時追記: セキュリティ担当者なら自社サービスドメインのCTログをモニターして不正証明書が発行されていないか監視するといった関わり方が必要でしたね。実は過去自分も Meta が提供しているCTログモニターで監視をしていたのですが、通常の証明書発行時の通知がうざくなってしまい途中で止めてしまいました。何かアノマリー検知みたいな仕組みと組み合わせないとCTログの監視はちょっと大変かなと思いました。
CAA(CA に対する認証)
CAAは、証明書を発行できる認証局をDNSレコードに登録し、登録されていない認証局からの証明書発行を防ぐ機能です。これは、認証局による不正な証明書発行に対してユーザが取ることができる唯一の防御策です。この節では、CAAの設定概要、導入方法、現在の課題などが説明されています。
本書には明確に記載されていないものの、私の経験から言うとCAAの難しい点は、CNAMEを使って複雑にドメインのエイリアスを利用している場合です。CNAMEドメインにはCAAレコードを直接設定できないため、CNAME先または上位ドメインにCAAを設定する必要があります。この際、CNAME参照とDNSツリークライミング(DNSの階層を遡ること)を考慮した設計が必要です。
当初の仕様(RFC6844)ではこの点が曖昧で、Errataで指摘されていましたが(現在のRFC8659では修正されています)、CNAMEを使って複雑なドメイン利用をしている場合は、特に神経を使いました。ただし、CAA導入自体はDNSにレコードを登録するだけであり、アプリケーションが直接CAAレコードを参照することは禁じられています。そのため、テストをしっかり行えば、CAA導入によるサービス運用への直接的な影響はかなり低いと言えますので、その点は安心できるでしょう。
一方で、CAAの導入は認証局の不正対策だけでなく、社内セキュリティガバナンスの観点からも大きな意味があります。大規模な組織では、特定の商用認証局に限定してサービス用ドメインの証明書を利用するケースが多いでしょう。しかし、サービス部門が組織認証を回避して、勝手にドメイン認証を行って他の認証局の証明書を利用してサービスを運用してしまうかもしれません。問題は証明書の発行自体ではなく、このようにセキュリティ内規に従わない(またはその存在を知らない)部門は、他にもシステムに何らかの脆弱性を残している可能性があることです。
最悪の場合、サービスドメインを含む証明書と秘密鍵が盗用されてフィッシングサイトに利用されるなどのセキュリティ事故につながる恐れがあります。CAAを導入することで、こうしたリスクをある程度コントロールできると言えるでしょう。内部的なセキュリティガバナンスを徹底する一つの手段としてCAAを導入すると言った面もあるかと思います。
この章ではCAA導入に関する手順が詳しく記載されており、非常に参考になります。大規模な組織だったりすると、もしかしたら知らない間にどこかの部署で違う認証局から証明書が発行されているもしれないという状況では、CTログを徹底的に調べる必要があります。さらに、CAA導入後には指定認証局から正常に証明書が発行される試験はもちろんですが、不正な証明書発行を防止できているか他の認証局からの発行テストも考えないといけません。CAA設定のチェックのためとは言え、リアルに不正な証明書の発行を試すのは背徳感があって非常にドキドキします。しかし、実際に体験するとCAAの導入がもたらすセキュリティ向上の重要性を実感できるでしょう(当然ですが実際にテストする場合は、認証局の業務に迷惑を掛けないよう十分に配慮して行いましょう)。
CAAに関しては、私のブログでもその仕組みを紹介しています。この章を読んでCAAについて理解を深めたい方は、より詳しい情報を得るためにぜひ私のブログをご覧いただければと思います。
パート2: 信頼を支える基盤、セキュリティプロトコル、その実装であるライブラリとプログラムが抱えるさまざまな問題(第5章〜第8章)
このセクションでは、PKI、HTTP、ブラウザ、実装、そしてプロトコルの問題点や攻撃方法について詳しく解説しています。20年以上前に起きた問題から最新の課題までを網羅し、TLS/PKIが直面している問題や課題の歴史的背景を学ぶことができる非常に価値のあるパートです。各問題は複雑で深いものが多いですが、歴史的な謎解きを楽しむような感覚で、過去の問題が現在のTLS/PKI技術にどのように反映されているかを学んでいただければと思います。
PKI に対する攻撃のアップデート
PKIの問題については、カザフスタン政府による傍受用のルート証明書の導入騒ぎと Symantec の Distrust について追記されています。その時の自分の一言tweetコメントを載せておきます。
おぃおぃ、国家的にMiTMやると宣言しているカザフスタン政府が、堂々とMozillaにRootCAの登録を申請しているわ。 / “1232689 – Root Certification Authority of the Rep…” https://t.co/nIjcB30E8Z
— Shigeki Ohtsu (@jovi0608) 2016年1月8日
GがSymantecに激おこの件。誤発行数の多さというよりシマンテックの証明書発行システムを十分なチェックなしに他の組織に使わせていたことと指摘されてもそれをちゃんと開示しなかったことが原因なのね。テスト証明書がこんなにもある https://t.co/sBTB2707dP
— Shigeki Ohtsu (@jovi0608) 2017年3月24日
HTTP/ブラウザ問題のアップデート
このアップデートでは、皆さんが日常的に使用しているブラウザーにおけるEV(Extended Validation)証明書の表示がなくなった背景と、証明書失効のメカニズムにおけるOCSP Staplingの機能について詳細に追記されています。EV証明書の表示がなくなったことと、Chromeブラウザの表示アイコンが変わったことについては、少し古い情報ですが、私のブログでも解説しています。興味がある方は、ブログも合わせてご参照いただければと思います。
jovi0608.hatenablog.com
jovi0608.hatenablog.com
本書では、現行PKIの証明書失効機能の問題点と限界に関して深く掘り下げています。それを読むと現在のPKIシステムに少し悲観的になるかもしれませんが、OCSP stapling は、ユーザーのプライバシー保護と証明書失効メカニズムを少しでも改善するために実行可能な数少ない手段の一つであり、現状でも対応する価値は十分にあると思います。しかしこの先は現状の証明書失効メカニズムを改善していく方向ではなく、短期証明書の導入を拡大し、失効機能に依存しない新しい対策へと移行していくだろうと予測しています。
実装の問題、プロトコルに対する攻撃のアップデート
このセクションは、幅広く深いセキュリティ知識が求められる部分です。特に、プロトコルの基本的な構造に起因する脆弱性は、これまでの専門家によるプロトコル設計に対する深い考察を裏切るようなものが多いため、これらを理解することはTLS 1.3への深い洞察に繋がるでしょう。しかし、この理解への道は困難であることを覚悟してください。
今回のアップデートでは、STARTTLSの実装に関する脆弱性、TLS 1.3のダウングレード攻撃防止機能、ALPACA、ROBOT, Racoon攻撃、そしてKCI攻撃についての内容が追加されています。KCI攻撃については、私のブログで詳しく解説しています。少し難しい内容かもしれませんが、図を使って丁寧に説明していますので、興味のある方はぜひ参照してみてください。
ROBOT(Return Of Bleichenbacher’s Oracle Threat)攻撃についての記述は衝撃的でした。1998年に発表されたRSA PKCS #1 v1.5のエラー処理対するBleichenbacher攻撃という脆弱性が、約20年後も多くの商用製品で未解決のまま残っているという事実です。開発者としてはエラーをすぐに処理したいという本能的な願望がありますが、その急ぎ足が逆に脆弱性を生む原因になり得てしまいます。結果暗号実装では、さまざまなサイドチャネルを考慮する必要があり、セキュリティに関わる実装の難しさを改めて感じさせられる事例でした。
ROBOTのまとめ:F5,Citrix,Radware,Cisco,Erlang,Bouncy Castle,WolfSSLには、TLSのRSA PKCS#1v1.5を使った鍵交換で復号処理に問題があるためBleichenbacher攻撃を受ける可能性があります。早くアップグレードしましょう。脆弱性を問い合わせても製品が不明なものがまだ存在しているらしいです。
— Shigeki Ohtsu (@jovi0608) 2017年12月12日
Racoonについては、以下のツイートがその内容を一言でまとめています。「やはり暗号実装は難しい」。これも暗号技術の実装における複雑さと難易度を端的に示している例と言えるでしょう。
TLS1.2以下で固定DHで鍵交換している場合、共有鍵がゼロ始まりだと削除する仕様になっているため、その後のPRFハッシュで計算速度が変わり、サイドチャネル攻撃が可能であると。 / “Raccoon Attack” https://t.co/p7WDzYgFMO
— Shigeki Ohtsu (@jovi0608) 2020年9月10日
パート3: 安全かつ効率的な設定でTLSをデプロイするための情報(第9章〜第10章)
このセクションでは、パフォーマンス、HSTS(HTTP Strict Transport Security)、CSP(Content Security Policy)、ピニング、そして設定ガイドについて述べられています。最新のアップデートでは、QUICとHTTP/3の概要が新たに追加されました。
ピニングについては、第1版で紹介されていたブラウザ向けのHPKP(HTTP Public Key Pinning)が廃止された背景が説明されています。他方、アプリケーションでは不正行為や攻撃を防ぐために証明書ピニングが求められる場合があり、ピニングを利用する際の注意点や方法などが新しく追記されています。
パート4: OpenSSL(第12章〜第13章)
改訂前の「プロフェショナル SSL/TLS」では、Apache、Java/Tomcat、MS Windows/IIS、Nginx といった具体的なアプリケーション設定を解説した章がありましたが、改訂版ではOpenSSLだけ残し他はなくなりました。このパートで OpenSSLの使い方とOpenSSLコマンドによる動作検証のやり方など記述しています。
一つ残念だったのは、本セクションは OpenSSL1.1.1ベースで解説されていますが、既に2023年9月にEOLになってしまったことです。ただし実際に確認したところ OpenSSL3系では出力が少し違うだけで、それほど大きく違う箇所はありませんでした。手順や出力では、SEED-SHAなど古い暗号が使えなくなったことを注意すれば良いかと思います。 またTLSの古い機能を調べるためにサポート切れ OpenSSL-1.0.2g での使い方も追記されていますが、こちらは手元でコンパイルして検証用途だけに限定して使いましょう。
今回新たに追加された内容には、OpenSSLのセキュリティレベルに関する説明、TLS 1.3の設定手順、OpenSSLの初期設定方法、そしてSession Resumption(セッション再開)の手順が含まれています。
「13.11 セッションリザンプションの動作を確認する」セクションでは、OpenSSLのバグのためにTLS 1.3では-reconnectオプションを使用してセッション再開の動作を確認することができないという注記が追加されています。しかし、バグ自体は直っていませんが、替わりにOpenSSL-3.xではs_clientにCコマンドを直接送信することでTLS 1.3の再接続を実現できるようになっています。TLS 1.3を使用するクラスター環境で、チケットなどのリザンプション機能のテストが必要な場合は、この方法を試してみると良いでしょう。
$ echo C | openssl s_client -connect example.jp:443 Connecting to XXX.XXX.XXX.XXX CONNECTED(00000006) (中略) New, TLSv1.3, Cipher is TLS_AES_256_GCM_SHA384 Server public key is 2048 bit This TLS version forbids renegotiation. Compression: NONE Expansion: NONE No ALPN negotiated Early data was not sent Verify return code: 0 (ok) --- RECONNECTING Connecting to XXX.XXX.XXX.XXX CONNECTED(00000006)
このOpenSSLのセクションは、おそらく本書の中で私が最も頻繁に参照している部分です。同様の内容を扱う他の書籍はほとんど見かけません。OpenSSLのコマンド、機能、引数、設定値は非常に多岐にわたるため、通常はOpenSSLのマニュアルやソースコードを確認することが多いですが、それは面倒な作業です。なので、まずはこの章に記載がないかを探すようにしています。特に、プライベートCAを作成し、検証用の証明書を自分で発行する際、OCSPサーバーの設定方法まで記載されており、大いに役立っています。
自分でプライベート認証局を設立し、ルート証明書を自分のブラウザの信頼リストに追加することで、様々な検証を行うことができ、TLS/PKIに関する技術的な知識が大きく広がります。まだ試したことがない方は、PKIの仕組みを体験する意味でも、OpenSSLを使って自分のプライベート認証局を作成してみることをお勧めします。
本書でTLS 1.3を理解するためのちょっとしたアドバイス
ここまで改訂版のアップデートとTLS/PKI技術の内容に焦点を当ててきましたが、次に第2章を読んでTLS 1.3をより深く理解するために、いくつか私なりのアドバイスをご紹介したいと思います。
1. Record層の形式について。
「2.1.1 Record プロトコルの形式」セクションでは、TLS 1.3のRecordプロトコルがミドルボックスの影響を受けて形式的なプレースホルダーになっていることが説明されています。Record層やClientHelloのバージョン番号の透過性に関して、以下の私のブログでより詳しい情報を提供しています。
このブログでは、このような状況がなぜ生じたのか、どれくらいの影響があるのかについての背景と詳細が理解できます。また、本書の「7.7.2 相互運用性の問題/バージョンに対する不寛容」、「7.7.7 将来の相互運用性の問題を防ぐGREASE」、そして「9.1.5 QUICとHTTP/3」のOssificationの節も合わせて読むことで、ここで述べられている内容の理解が深まるでしょう。
2. ハンドシェイクメッセージの構造は、実際に目で見て確かめる。
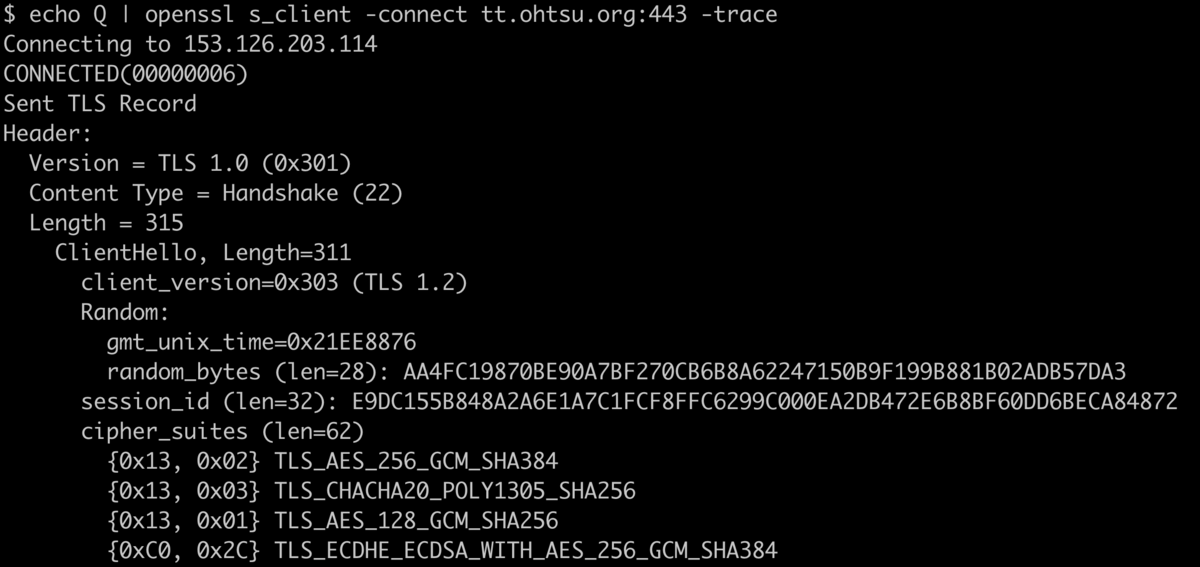
TLS 1.3は、暗号化通信に迅速に移行するため、Wiresharkなどのパケットキャプチャツールを使って通信内容をすべて確認するのは大変で、手間のかかる作業になります。しかし、ただ本に書かれたハンドシェイクの説明を読むだけでは、実際の動作についての実感は得られないでしょう。プロトコルを学ぶ基本は、実際のプロトコルデータを自分の目で見て理解することから始まります。OpenSSLのコマンドを使えば、比較的容易にハンドシェイクメッセージの中身を見ることができます。そのためには-traceオプションを試してみると良いでしょう。
$ openssl s_client https://example.jp/ -trace
-trace オプションを使用すると、実際のTLSハンドシェイクの詳細な内容を見ることができます。サーバ側とクライアント側で様々な設定を試しながらハンドシェイクの中身を確認し、各フィールドや拡張がどのような意味を持っているのかを調査し、考察しながらデータを分析することをお勧めします。このように実際のデータを直接見ることで、TLS 1.3に関する理解が大きく深まるはずです。
3. 暗号に関する数式は、そんなものと最初は深入りしない。
暗号技術は、第1章でも少し触れられているように、非常に複雑で難解な分野です。すぐに深みにはまり、困難に直面することも多いでしょう。最初のうちは、深入りしすぎないように注意しましょう。ただし、読み進めていると、突如としてわけの分からない数式が登場することがあり、それに戸惑うかもしれません。以下のような数式が出てきたときに、理解が止まってしまわないように、ある程度のその先の手がかりを確保しておくと心理的に楽になります。
AEADEncrypted = AEAD-Encrypt(write_key, nonce, plaintext, additional_data)
はい、暗号技術の少し深い部分を理解するための入り口として、私のブログがお手伝いします。
TLS 1.2で使用される形式について、ChaCha20-Poly1305のAEAD(Authenticated Encryption with Associated Data)に関する解説は、こちらのブログに、 jovi0608.hatenablog.com
そしてAES-GCMのAEADについてはこちらのブログに、少し簡単に書かれています。興味がある方はぜひ参照してみてください。そうすることで、AEAD-Encrypt関数に関するイメージが少しは明確になるのではないかと思います。
また本章では、TLS 1.3の鍵導出と鍵スケジュールに関して、「2.5 暗号に関する計算」という節でかなりのページを割いて詳細な解説をしています。多くの読者が「なぜこんなに複雑な手順を踏むのか?」という疑問を持つことでしょう。本書では、『「1 つの鍵は 1 つの用途にしか使わない」というのが暗号学における原則です。』の一文で済ませてしまってますが、この疑問に対するもう少し詳しいヒントを、以下のツイートで少しだけ触れていますので、参考にしてみてください。
TLSの鍵導出とかで使われるラベルって意味あるのかわからん。暗号強度的な意味では絶対なさそうに思えるんだけど。TLS1.3だとさらにラベル増殖してるみたいねw
— Kanatoko (@kinyuka) 2022年9月13日
.ラベルで用途ごとに鍵を分離し、HKDF自体破られてなければ、仮に一つの鍵が漏洩等で危殆化しても他に影響が及ぶことを防ぐためです。仰るとおり暗号強度自体変わらないですが将来的に色んな合わせ技による攻撃があってもその影響を限定的にしたいという意図があります。
— Shigeki Ohtsu (@jovi0608) 2022年9月14日
.はい。もともとは鍵分離することで分析範囲が限定され形式証明とかやりやすくなる、という安全性解析側からの要請で導入されることになったようです。
— Shigeki Ohtsu (@jovi0608) 2022年9月14日
4. 拡張についていったん横に置いておくけど頭に残しておく。
原著者は、TLSに対する全体的な理解のためには拡張の詳細を深く知ることが必ずしも重要ではないと述べており、そのため本書ではTLSの拡張については詳しく解説せず、仕様への参照を促しています。確かに、TLSの拡張は種類も機能も多岐にわたり、詳しく解説すると理解が難しくなる可能性があります。しかし、TLS 1.3はTLS 1.2と形式的な互換性を保つため、多くの機能を拡張領域に組み込む方針で再設計されています。個人的にはこれらの拡張はもはやプロトコルの核心部分そのものだと考えています。全体的な理解のためには必要ないかもしれませんが、TLS 1.3の本質を深く理解するためには、いずれ重要な拡張機能についての理解を避けては通れないでしょう。
現在、TLS拡張は0番から61番までがアサインされています。本書でも参照されていますが、詳しい一覧はこちらのIANAのページ
Transport Layer Security (TLS) Extensions
にあり、TLS 1.3でどのハンドシェイクに使われるかのタグが付いています。全体的な理解を深めた後で、さらに詳細を知りたくなったら、TLS 1.3仕様で定義されている拡張(参照がRFC 8446になっているもの)に注目してみてください。これらの拡張を理解することで、TLS 1.3のより深い理解につながるでしょう。
5. 0-RTT についてより深く知りたいなら。
TLS 1.3の新機能である0-RTTを理解することは、TLS 1.3の理解においてクライマックスに相当する段階です。第2章のまとめで「ただし、0-RTTでは常に前方秘匿性が有効になるわけではない。それでも旧バージョンよりはましだ」と述べられています。このポイントを深く理解するには、実際に0-RTTの前方秘匿性を破る実験をしてみることが最も効果的です。詳しい解説は以下のブログで行っていますので、意欲のある方はぜひ課題に挑戦してみてください。
jovi0608.hatenablog.com
jovi0608.hatenablog.com
もっとゆるく学びたい人へ(リアルTLSハンドシェイク演習)
以前、「プロトコルを学ぶ基本は実際のデータを目で見ることから始まる」と述べましたが、次のステップとして「実際にプロトコルデータを作成し、送受信する」ことが理解を深める上で非常に効果的です。自分でTLSクライアントをプログラムして、既存のTLSサーバに対してデータを送り、応答を解析することで、さらなる理解が促進されます。実際にデータを扱うことで、理論だけでは得られない深い洞察や実践的な知識が身につくでしょう。
とはいうものの、実際にプログラムを書くことに躊躇される方もいるでしょう。もう少し気軽に学びたい方には、リアルTLSハンドシェイクの演習を試してみることをお勧めします。これは、前職で行った大学の社会人コースの講義で使用した演習課題です。参加者は2人1組になり、クライアント役、サーバ役に分かれてポストイットにTLSハンドシェイクのデータを模して記述し、お互いに交換します。なんちゃってDH鍵交換やハッシュ計算など行い、最終的には机の上に並んだ色とりどりのポストイットを通じて実際にどのようにTLSのセキュリティ通信が実現されているのかを体感できます。この方法は、受講者からも「実際のTLS通信プロセスを実感できた」という感想もいただいています。

この演習はかなりゆるいものですが、もしご自身がグループで本書を輪読する機会があれば、以下のレポジトリにTLS 1.2の課題が用意されていますので、実際に試してみてください。そして、TLS 1.3ではどのように違ってくるのか、その探求を皆さんの宿題として挑戦してみてください。学びを深めるために、是非ともこの機会を利用して頑張ってみてください。
FLoCとはなにか
1. はじめに
Google がChrome/89よりトライアルを開始しているFLoC (Federated Learning of Cohorts)技術に対して、現在多くの批判が集まっています。 批判の内容は様々な観点からのものが多いですが、以前より Privacy Sandbox に対して否定的な見解を示してきたEFFの批判「Google Is Testing Its Controversial New Ad Targeting Tech in Millions of Browsers. Here’s What We Know.」が一番まとまっているものだと思います。
これまで Privacy Sandbox 技術に関わってきた身としては、各種提案の中でFLoCは特にユーザへの注意が最も必要なものだと思っていました。しかし、これまでのド直球なGoogleの進め方によって、FLoCのトライアル開始アナウンスから即炎上という流れに結果的になってしまったことは非常に残念で、なかなか複雑な気持ちで見守るしかありませんでした。
このエントリーを書くにあたり、各種批判を否定するつもりは全くありませんし、このブログを読んで頂いた方にその考え直してもらいたいとも思いません。いくつかの批判を読むと自分でも納得する指摘もあります。
しかし先日、個人的に FLoC Simulator を作成して、いくつかFLoCの不明点をGoogle側に確認し、そのシミュレーションを行いました。「FLoC Simulation and Algorithm #95」 その際、FLoCを実際に自分の手で計算してみると「なるほどなぁ、こんな仕組みだったのか」と関心してしまうことが多かったのも事実です。
そこで、今騒がれている FLoC とはいったいどういう技術なのか? どうやってidを生成しているのか? その中身を純粋に広く知ってもらうのもよいのではないかと考え、自分の備忘録として書いてみたいと思います。
結局、長いエントリーになっちゃいました。長文嫌いな方は、読むのを避けてください。
2. Disclaimer
繰り返しになりますが、このエントリーはFLoCの技術的な仕組みについてだけ書いたものです。 技術以外の部分、例えばFLoCに関する倫理的・法的な問題などについては全く触れるつもりはありませんので、ご了承ください。
3. Privacy Sandboxとは
Googleが提唱しているPrivacy Sandboxは、大きく以下の2つを機能を実現することを指します。
- ブラウザフィンガープリントやキャッシュ探索などによる隠れた(covert) tracking の防止
- 3rd party cookie の廃止に伴う代替技術群の実現
その目的は、ユーザプライバシーに(一定の)配慮をしながらWeb上の広告エコシステムを(ある程度)維持していくことである、と私は理解しています。
現在のChrome/90で Privacy Sandbox の Origin Trial (OT) を開始しているのは、Trust Token API、 Attribution Reporting API (旧 Conversion Measurement API)、 First Party Set、 FLoC の4つになります。
OTとは、Chrome に導入された先行試験実装に対して token をサイトに仕込み、期限限定で試験機能の評価・検証を行う仕組みです。昔、先行試験機能はベンダープレフィックスなどを使ってリリースされていましたが、いつの間にか試験機能のAPIが広く使われて固定化されてしまう事例が発生しました。OTはその問題(API Burning)を避けるために開発されました。
Privacy Sandbox で提唱されている新機能の多くは、W3CのWICG(Web Platform Incubation Community Group)上で仕様ドラフトが議論されます。ChromeではこのOTを通じて Privacy Sandbox のフィールド試験が進められ、その効果や仕様の見直しなどが行われます。WICGで議論・検証された仕様ドラフトが十分評価されれば、晴れて将来的に標準化への道が拓ける見込みになります。
他のPrivacy Sandboxの各機能を説明すると、それぞれブログが数本書けてしまうほどなので、ここではFLoCだけに限定します。
Privacy Sandboxの技術の中で特に広告技術に関連した提案には、鳥にちなんだコード名が付けられます。FLoCは、英語で「群れ」を表す「flock」に掛けていると言われています。
現在のOTは、 FLoC の頭文字になっている Federated Learning(連合学習) を利用していませんので注意してください。当初Googleは連合学習を利用したアルゴリズムを検討したけれども、結局今回のOTでは連合学習を使わない方法になり、しかし名前を変えずにそのままにしてあるといった経緯のようです。
以下、FLoCの説明については、2021年5月時点でOTを行っている "chrome.2.1" のアルゴリズムバージョンをベースに話を進めます。 現在のFLoC OTは、アルゴリズムの効果測定や評価検証も大きな目的の一つですので、将来的にFLoCアルゴリズムが大きく見直される可能性が高い、ということを前提にエントリーを読んでください。
4. FLoCとは
Googleを始めとしてWeb上で提供されている広告は、一般的に大きく以下の3つのカテゴリーに分かれてます(自分はadtechの専門家じゃなく、世の中にこの3種類しかないとはっきり断言できないので、他にもあるかもしれません)。
- コンテンツ連動型広告(Contextual Advertising)
- ユーザーの興味/関心に基づく広告(Interest-Based Advertising)
- 追従型広告(Remarketing/Retargeting)
FLoCは、2の「ユーザーの興味/関心に基づく広告(オーディエンス ターゲティング)」に用いられる技術です。FLoC によって一定期間内ユーザの閲覧履歴、主に広告表示されているサイトドメイン(eTLD+1)の履歴が、数千人単位でグループ化されます。
ただしFLoCだけで全てが実現できるわけではありません。FLoCは単純にユーザグループに割り振られた番号(Cohort Id)を出力するだけです。そのidと広告主やadtechベンダーが持つオーディエンスデータ(ユーザ属性・興味・関心・購買志向のデータ)を組み合わせることによって、初めてFLoCを使ったオーディエンス ターゲティングが可能になります。
実はこのオーディエンス ターゲティングは、現在でも 3p cookie を最大限に利用して実現できているものです。
3p cookie はユーザ行動を第3者に丸見えの状態にし、これまでそのデータを活用してオーディエンスデータの収集・分析が行われていました。世間からの要請もあり Googleは 3p cookieを廃止し、ダダ漏れ状態であるユーザの閲覧履歴を収集できないようにすることを決めました。しかしその代わりに、ユーザの閲覧行動をブラウザ内に閉じた処理で数値化し、それを数千人単位にまとめるFLoCを開発しました。これで現在よりもユーザプライバシーが配慮された、かつこれまでと同じぐらいの効果を持つオー ディエンス ターゲティングが実現できるであろうとの考えです。「今までよりマシな仕組みを作ったのになんでこんなに非難されなきゃいけないの?」といった愚痴が聞こえてきそうです。
5. FLoC Simulator
今までよりマシで効果も高い、と言われても本当にそうなのか。技術的にその仕組をちゃんと知っておきたいものです。そこでFLoCの仕組みを理解し、効果を評価できるよう Chrome のFLoCアルゴリズムの実装部分をそのままGoに移植した FLoC Simulator を作成しました。
FLoC Simulator は、7ドメイン以上のホストリストをJSON形式で用意すると(host_list.json)、コマンドラインで Cohort Id を出力してくれるものです。
例えばこんなドメインリストでは、以下のような Cohort Idが計算されます。
$ cat host_list.json [ "www.nikkei.com", "jovi0608.hatenablog.com", "www.nikkansports.com", "www.yahoo.co.jp", "www.sponichi.co.jp", "www.cnn.co.jp", "floc.glitch.me", "html5.ohtsu.org" ] $ ./floc_sample host_list.json domain_list: [nikkei.com hatenablog.com nikkansports.com yahoo.co.jp sponichi.co.jp cnn.co.jp floc.glitch.me ohtsu.org] sim_hash: 779363756518407 cohortId: 21454
上記シミュレーションでは、21454 の Cohort Id が計算されています。検証・比較のため、下図の同じドメイン履歴を持つ Chrome でも同じ 21454 が出力されているのがわかります。


ソースを見ていただければ、わずか数キロバイトの処理とGoogle側のサーバから配布されるファイルを組み合わせてCohort Idの計算が行われていることがわかります。関数や変数名はできるだけChromeの実装に合わせています。
6. FLoCの仕組み
FLoCアルゴリズムのコア部分は、データマイニングなどの分野で利用されている Locality Sensitive Hash(LSH: 局所性鋭敏型ハッシュ) という技術を使います。 これは似たような文章を探したり、同じ特徴を持つ画像を探したり、といった最近傍探索(Nearest neighbor search) で利用される技術です。FLoCではLSHの一種であるSimHashが採用されています。 SimHash は 、16年ほど前にGoogle検索で(ほぼ)重複したWebコンテンツ(near-duplicated web contents)を検知するのに使われていたアルゴリズムです。
6.1. だいたいのFLoC計算の流れ
Chrome内で行われているFLoCの処理は、おおよそ以下の4つの部分に別れています。
- navigation時にFLoC対象のページ履歴にフラグを付ける
- 7日間に一回、履歴からSimHashを計算し、Chrome SyncでGoogle側に送る
- (FLoCバージョンで1回実施) Google側でユーザのSimHashをまとめ上げてクラスター化する。ブロックするCohort Idを特定し、クラスターファイルを生成し、全Chromeユーザーへ配布する
- サイトのFLoC APIの実行に伴い、SimHashとクラスターデータから Cohort Id を計算し、出力する

このうち 3. は、事前にGoogle側で処理が行われます。OT期間中に再度3の一部処理が行われ、FLoCバージョンが更新される予定であると github issue で回答がありましたが、現在のところまだ実施されていません。
6.2. FLoCアルゴリズムの詳細
各ステップをもう少し細かく見ていきましょう。
6.2.1. navigation時にFLoC対象のページ履歴にフラグを付ける
ユーザが navigation したページが、以下の3つの条件が全て満たされる場合に FLoC の計算対象となります。
- navigation の IP がPublicルーティング可能であること
- メインドキュメントの permission policy がFLoCを許可していること
- 広告が表示されているページ、又は FLoC API (document.interestCohort()) が実行されているページであること
navigation 完了後ユーザ履歴に保存される際に、上記FLoCの対象ページかどうかのチェックが行われ、フラグが付けられることになります。
実は 1. のIP チェックは socket アドレスに対するものなので、「Private IPを持つ内部Proxy経由で外部のサイトを閲覧した場合、全部 FLoC の対象外になっちゃうんじゃない?」とgithubで聞いたら、「試してないけどそうなる」との回答でした。FLoCの利用を回避するハックとして使えるかもしれません。興味のある方がいらっしゃれば検証してください。
6.2.2. SimHashを計算する
ユーザ履歴が7ドメイン以上残っている場合、履歴中の ドメインデータ (= eTLD+1) から計算されます。SimHash計算は、7日毎 にスケジュールされています。
現在の FLoC OT のコアアルゴリズム、LSHの一種であるSimHashとはどういうものでしょうか?
Hashという名前が付いているように、SimHashは任意のサイズのデータを一定の小さなサイズに変換させる機能を持ちます。5年前に20億人を超えたと公表されたChromeユーザは、現在では世界で7割近くのシェアを持つと言われます。FLoC計算対象となるChromeユーザの履歴パターンは膨大なものになるでしょう。それを使えるようにするには、一定のサイズ以下に収めないといけません。そのためユーザ履歴のHash化は必須です。
しかし通常利用されるSHA256などの暗号学的ハッシュをユーザ履歴に適用すると、データサイズを減少させることはできるものの、ハッシュ後は複数の元データ間の関連性をうかがい知ることはできません(原像攻撃に対する防止)。
先に述べたLSHは、似ているデータを近いハッシュ値に変換させるのが特徴です。そこで FLoC の SimHash では、データを多次元ベクトルで表現し、データ間の近さを表す指標としてベクトルの角度を利用します。 SimHashのキモは、いくつかランダムなベクトルを用意し、ユーザデータとランダムベクトルとの角度の関連性からデータの類似性を導出し、同時により低次元のベクトルにサイズを減らす変換を行うことにあります。
あるユーザデータのベクトル(User)に対して1bitのSimHashを計算する場合、1つのランダムベクトル(rv)を用意して下図のような計算を行います。赤色のrv と User のベクトル角度θに注目し、cosθが正値又は0の場合は1,負値の場合は0のビットで表します。この場合2つのベクトル内積の値を計算すると正負が求められます。
 赤色rvと垂直な平面(破線のrandom hyperplane)から見てみると、ユーザベクトルの先が赤色破線上部のエリアにいるとSimHash=1となり、下側にいると0になります。SimHash:1の複数ユーザデータ間で比べると、SimHashが1のデータは似ているもの、0のユーザデータは似ていないもの、と区別することができます。そしてユーザデータは類似する1bit値にハッシュ化されました。
赤色rvと垂直な平面(破線のrandom hyperplane)から見てみると、ユーザベクトルの先が赤色破線上部のエリアにいるとSimHash=1となり、下側にいると0になります。SimHash:1の複数ユーザデータ間で比べると、SimHashが1のデータは似ているもの、0のユーザデータは似ていないもの、と区別することができます。そしてユーザデータは類似する1bit値にハッシュ化されました。
1つのユーザデータを1bitのSimHashに変換するだけではわかりにくいので、2つのユーザデータ(UserA、 UserB)を使い、3bitのSimHashに変換してみます。
下図の様に、赤・緑・青の3つのランダムベクトル(rv1, rv2, rv3)を用意します。3種類のランダムベクトルとユーザベクトル(UserA, UserB)の角度でSimHash Bitを決めます。その結果、UserA の SimHash は 100、UserB の SimHash は 101 となることがわかります。。頭2bit分だけ同じの3bitハッシュ値に変換されたことになります。もしUserB の角度がもう少しrv3の random hyperplane を超えて User A に近ければ同じハッシュ値になっていたでしょう。
 ランダムベクトルが増えていけば、囲い込まれる部分が狭まり、複数のユーザデータの類似性をより精度高く比較することができます。FLoC では、50個のランダムベクターを使い、ユーザ履歴の情報を50bitのSimHashに変換させます。
ランダムベクトルが増えていけば、囲い込まれる部分が狭まり、複数のユーザデータの類似性をより精度高く比較することができます。FLoC では、50個のランダムベクターを使い、ユーザ履歴の情報を50bitのSimHashに変換させます。
6.2.3 ユーザ履歴のドメインデータをベクトル化し、SimHashを計算
では、ユーザ履歴のドメインデータをどうやってベクトル化するのか。インターネット上のドメイン(eTLD+1)の上限数を決めることはできません。そこでGoogleが開発した CityHash64 という非暗号学的ハッシュを使い、ドメイン名を64bitの数字に変換します。そうすると任意のドメイン名が、264個のどれかの数字にマッピングされます。そこでドメイン履歴を264次元のベクトルにして、該当するドメインはドメイン名のCityHash64値をインデックスの要素値を1としたベクトルとして表します(one-hot domain encoding)。
example0.com ドメインの場合、CityHash64をかけると 3771499692761966109 になります。example0.com ドメインのユーザ履歴は、3771499692761966109番目の値を1にした264次元のベクトルに変換するわけです。
その結果、例えばユーザが [example0.com, example1.com, … , example99.com] のドメイン履歴を持っているとしたら、それぞれのドメイン名のCityHash64値番目のインデックスが1となるベクトル(0,...,1,...,1,..1,...,0)のような、100個の1を持つベクトルになります。
このユーザ履歴のドメインベクトルを50bitのSimHashを変換するには、50個のランダムベクトルを用意します。ユーザごとにランダムベクトルが変わってしまうのは困るので、要素の位置をSeedにして決定論的に決まる乱数ベクトルを生成します(コード中では randomGaussian 関数を指します)。こうすれば異なるブラウザ内でもユーザごとに変わらず、同じ乱数ベクトルを生成できます。
ここで生成したガウス分布の乱数ベクトルとユーザ履歴ドメインのベクトルとの内積を取ると、下の図の様に単純に乱数値を加算することと同じになり、加算後に正負を判定すると SimHash ビットを求めることができます。これを50個のランダムベクトルに対して同じ処理すれば、50bitのSimHashの計算が完了です。
 SimHashのコアアルゴリズムのコード部分を以下に示します。SimHashの計算自体、非常にスッキリしていることがわかるでしょう。
SimHashのコアアルゴリズムのコード部分を以下に示します。SimHashの計算自体、非常にスッキリしていることがわかるでしょう。
func simHashBits(input []uint64, output_dimention uint8) uint64 { var result uint64 = 0 var d uint8; for d = 0; d < output_dimention; d++ { var acc float64 = 0; for _, pos := range input { // randomGaussian は2つの整数をSeedにしてガウス分布の乱数を生成する関数 acc += randomGaussian(uint64(d), pos) } if (acc > 0) { result |= (1 << d) } } return result } func SimHashString(domain_list []string) uint64 { var input []uint64 for _, domain := range domain_list { hash := CityHash64V103([]byte(domain)) input = append(input, hash) } sim_hash := simHashBits(input, 50) return sim_hash }
早速 floc_simulator で、example0〜98.comまで一緒で最後の100個目のドメイン履歴(example99.com と example100.com)が異なる場合のSimHashを計算してみます。
SimHash([example0.com, example1.com, ..., example98.com, example99.com]): 10011000111000001101111010001011010110010000010110 (672366295082006) SimHash([example0.com, example1.com, ..., example98.com, example100.com]): 10011000111000001100111010001011010110010001010110 (672365221340246)
上記の通り、50bit中48bitが同じで2bit分が異なるSimHash値が計算できています。このデータを使えば、ユーザ閲覧ドメインの類似性が評価できます。
6.2.4. SimHashのクラスター化とセンシティブ情報のブロック
ブラウザー内でSimHashを計算できればFLoCは終わりではありません。 SimHashでユーザ履歴のドメインリストが近いユーザ集団を特定することはできますが、SimHashの値をそのまま利用すると以下の問題が発生します。
- 同じSimHashを持つユーザが少ない場合、個人が特定される恐れがある。
- センシティブなカテゴリーの割合が多いユーザ履歴では、センシティブな情報に偏ったCohort Idが生成されてしまい、本来他人に知られたくないセンシティブなユーザ情報が第3者にわかってしまう。
そのためFLoCではSimHashの値をそのまま利用することはせず、計算したユーザのSimHash値を一旦Google側に送り、いくつかまとめるクラスタ化処理を入れます。 Googleへのデータ送信は、ユーザ履歴やプロファイルなどをGoogleアカウントと一緒に同期する Chrome Sync の仕組みが利用されます。
Google側でのSimHashのクラスタ化では以下の2つの処理が行われます。
- ユーザから送られたSimHash値をソートし、2000人以上のユーザを含むようにSimHash群に分割する。SimHashの分割群に対して小さい順にIdを割り振りCohort Idとする。
- Cohort Id 内に含まれるドメインを洗い出し、センシティブなカテゴリーを含む割合が平均より10%以上大きければそのCohort Idに対して blocked のフラグを付ける。
ここではSimHashを集めてソートして分割しているだけなので、教師あり学習を全く実施していません。なので現在のFLoC OTは、連合学習(Federated Learning)を利用していないということになります。
センシティブなサイトのカテゴリーとして、Googleは以下の項目を定義・管理しています。もちろん具体的なサイトがどこなのかは非公表です。
- 禁止カテゴリ: アルコール、ギャンブル、カジノ、臨床試験の被験者募集、制限付き薬物に関するもの、13歳未満のユーザ
- 個人的な苦難: 健康、厳しい経済状況、人間関係、犯罪、虐待や心的外傷、マイナス思考の強制
- アイデンティティや信条: 性的指向、政治的思想、政治に関するコンテンツ、労働組合への加入状況、人種や民族、信仰、社会的に阻害された集団、トランスジェンダーの性別認識
- 性的な関心: 避妊、性的なコンテンツ
- 機会へのアクセス(米国、カナダ向け): 住居、求人、クレジット情報
クラスタ化した結果のデータは、Google側がバイナリーファイルにまとめてcomponent updator によって各ユーザに配布されています。
MacOSの場合、FLoCのクラスターファイルは、~/Library/Application Support/Google/Chrome/Floc/1.0.6/SortingLshClusters として保存され、クラスターデータが1バイト長でエンコードされています(blocked flag:1bit長とクラスタのSimHashサイズのビット数:7bit長)。
SimHashからクラスターデータを使ってカウントすると下図のように Cohort Id が計算できます。
 現在 Cohort Id:2 がセンシティブカテゴリーを平均より10%以上の割合で含んでブロックされています。そこに当てはまった全てのユーザの Chort Idは、空の文字列が返されます。Cohort Id:2 以外にも全体の2.3%にあたる792個の Cohort Id がブロックされています。
現在 Cohort Id:2 がセンシティブカテゴリーを平均より10%以上の割合で含んでブロックされています。そこに当てはまった全てのユーザの Chort Idは、空の文字列が返されます。Cohort Id:2 以外にも全体の2.3%にあたる792個の Cohort Id がブロックされています。
SimHashの値に該当するスロットを見つければ Cohort Id の計算は完了です。5の例で計算した SimHash は 779363756518407 なのでちょうど21454番目のクラスターに入ります。例で示した通り Cohort Id は 21454 です。
クラスタ化の結果、Cohort Idの最大値は33871でした。各Cohort Idには最低2000人のユーザが含まれているので 33,871x2,000人=67,742,000人となり、最低でも6774万人以上のユーザ履歴データがGoogleで集計されていることがわかります。
クラスターデータが変わってしまうと過去のCohort Idとの互換性が損なわれてしまいます。今回のFLoCのOT中は、blocked の更新を行うことはするが、クラスタを変更を加えるようなアップデートは行わないと回答をもらっています。
7. まとめと今後
ということで、FLoCのCohort Id計算がどう行われているのか、技術的にかなり細かく説明しました。
example???.com というドメイン名を使った自分のシミュレーション結果では、1000ドメイン近くの履歴がないと多少の履歴の違いでも Cohort Id が異なってしまうという結果が出ました。一般のユーザが7日間に1000ドメインも閲覧することはなく、数十レベルだろうとのコメントをgithubでもらっています。もちろんハッシュをかけるドメイン名によって、シミュレーション結果はがらっと変わってしまいます。ドメイン数が少ないと少し履歴が違うだけで異なるCohort Idに計算されてしまうことが多いので、果たして現在のアルゴリズムでどこまで的確なオーディエンス ターゲティングができるのだろうか、と考えてしまいます。
また最近、ChromeのFLoCに関して、以下2つの処理が新しく入りました。
- SimHash計算に weight が導入された。
現在は全てのドメインが weight:1 で計算されています。今後どんな重み付けがされるのか。その結果 Cohort Id のオーディエンスは改善されるのか?
- FLoC対象とするページを API を利用しているページだけに限定するフラグが導入された。
もしかしたら批判を受けて、FLoC対象のページの条件をこれまで以上に制限する予定だろうか?
FLoCに対する批判はまだ止まりませんが、Googleも引き続きいろんな検討を進めていくのではないかと思っています。W3Cでの議論を注目したいです。
FLoC技術の参考情報
このエントリーを書くのに参考にした情報は、こちらにまとめています。
GnuTLSの脆弱性でTLS1.3の再接続を理解する(Challenge CVE-2020-13777)
(TLDR; めちゃくちゃ長くなったので、長文読むのが苦手な方は読まないようお願いします。)
1. はじめに
前回の「求む!TLS1.3の再接続を完全に理解した方(Challenge CVE-2020-13777)」 の記事にて、GnuTLSの脆弱性(CVE-2020-13777)のPoCを募集しました。 短い期間にも関わらず2名の方から応募を頂き、本当にありがとうございます。
また、応募しなかったけど課題に取り組んで頂いた方もいらしゃったようです。この課題を通じて、いろいろな方がTLS1.3仕様(RFC8446)に触れる機会を持っていただいたことを非常に嬉しく思います。
全くの初心者ではやはり課題が難しいとの意見もいただきました。今後はもう少し幅広い人に手をつけやすいよう工夫が必要であると感じていますが、はてさてどうしたらいいか、なかなか難しい。なんにせよ初めての試みでしたが、やってみてよかったと思っています。
2. 結果発表
応募を見させていただきました。結果、ペロトン(@prprhyt)さんが見事に解答されていると判断し、Vさんから(ブーストされた)3万円のアマゾン商品券と副賞として希望するラムダノート社の本1冊、私から1万円のアマゾン商品券を贈呈いたしました 。おめでとうございます!
応募内容を公開することを前提とした募集でしたので、この記事では応募解答についてコメントを付けながらTLS1.3の解説を進めます。
まずは課題の背景からです。
3. 課題の背景
今回のGnuTLSの脆弱性から課題を思いついたのは、前回のエントリーで述べた以下の理由です。
この脆弱性、実際にPoCを書いてみると非常に奥が深いです。TLS 1.3をちゃんと理解していないと無理です。
TLS 1.2 と TLS 1.3 でなぜ影響に違いがあるのか、そこはTLS 1.3の進化が見えるところです。またアナウンスには記述されていませんが、TLS 1.3の0-RTTを利用していた場合、この脆弱性によって大きな影響が新しく出てきます。
具体的にTLS1.2から1.3へどのような進化があったのかを見るには、その背景を理解しておくことが重要です。
そこで、今回の背景を理解するために必要な「Forward Secrecy(前方秘匿性)」と「TLS1.2におけるTicket方式の問題点」について説明します。
3.1. Forward Secrecy (前方秘匿性)
Forward Secrecy(前方秘匿性)は、TLSの機能を理解する上で非常に重要な概念です。ただ数年前私が初めてこの言葉に触れた時、何が「Forward」なのかすぐにわかりませんでした。
TLSを始めとした暗号通信は、通信している間だけセキュリティを確保できていればいいわけではありません。現在でもかなりのインターネット通信が傍受・保管されていると言われています。時間が経っても暗号通信した内容が外部に漏れないよう守られていることが必要です。
Forward Secrecyは、盗聴者が全部の通信データを保管しておき、数年後に暗号鍵が漏洩して通信データの内容がばれしてしまうリスクを防ぐ技術です。 「未来の安全」を確保するという意味で、時が進む「Forward」を指すと解釈して、やっと自分もこの言葉が腑に落ちました。日本語だと「通信後の秘匿性」という言葉にした方がわかりやすいんじゃないでしょうかね。

TLS1.2のRSA鍵交換は、クライアントで生成した暗号鍵(master secret)をサーバ証明書の公開鍵で暗号化し、サーバに送付します。この方法では、後日サーバ証明書の秘密鍵が漏洩すると、TLSハンドシェイクデータから master secret を入手することが可能になってしまいます。Forward Secrecyが保てません。
そのため、現在ではTLS1.2でRSA鍵交換の利用は非推奨です。代わりにセッション確立時に一時的(Ephemeral)に暗号鍵を生成するECDHEの利用が推奨されています。
ECHDEでも楕円暗号曲線で利用する秘密鍵は生成されますが、TLSハンドシェイクが終了したらもう必要なくサーバで保管する必要はありません。なので後日漏洩して危殆化する可能性はありません。(実際はメモリ中に一時秘密鍵が残っていることもかもしれませんが)
3.2 TLS1.2におけるTicket方式の問題点
しかしTLS1.2も、ECDHEを使っていれば大丈夫、どんな時もForward Secrecyが保たれて安全というわけではありません。通常複数のサーバでTLSを運用する場合、再接続時にクライアントが別のサーバに振られてフルハンドシェイクしないよう、セッションIDやTLS Ticket方式が利用されることが多いです。
セッションID方式では、複数サーバ間でセッション情報を共有しておく仕組みが必要です。大規模になるとなかなか運用していくのが大変です。
その点 TLS Ticket方式は、セッション情報を暗号化してチケットにしてクライアントに渡しますので、大規模なセッション共有システムは必要ありません。再接続時に送られたチケットを復号化する暗号鍵だけをサーバ間で共有しておけばいいので楽です。
しかしTLS1.2での Ticket方式は、チケットを暗号化した鍵が漏洩すると Forward Secrecy がなくなるという致命的な問題を持っていました。

チケットの中には、再接続用に master secretなど入ったセッションデータがまるまる暗号化されて入っています。後日もしなんらかの理由でチケットを暗号した鍵が漏洩し攻撃者に渡るとしたら、master secret を使って昔のTLSの通信データの中身が丸わかりになってしまいます。
そのためTLS1.2でTicket方式を使う場合、チケットの暗号鍵をいかに安全に運用・管理していくのかが大きな課題となっています。
そのような課題を克服するため、TLS1.3では再接続の仕組みを大きく変更し、チケット利用でForward Secrecyがなくなる、といったTLS1.2におけるTicket方式の欠点の解消される仕組みを取り入れました。
こういった背景を知っていただいた上で、ペロトンさんの応募解答を見ていきましょう。
応募解答 と コメント
ペロトンさんの応募解答のオリジナルは、Challenge CVE-2020-13777(MITM, 0-RTT Application dataの復元)にあります。 ここでは一部抜粋しながらフォロー記事を書いていきますが、ぜひオリジナルも参照してください。また今回の課題のフォローブログも掲載予定と聞いております。楽しみにしましょう(判明後URLリンクを入れます)。すぐ公開されました。
フォロー記事を書くにあたり、オリジナルの応募原稿をどう損なわずにのがいいのか色々試行錯誤してしまい、このブログを公開するのに時間がかかってしまいました。結局、自分のコメントは赤字で (コメント) ... (コメント終) の中に書いています。
ペトロンさんの図は黒色実線、私が作成した図は赤色破線で囲って区別できるようにしています。少し見苦しいと思いますが、誰が書いた文章なのかを間違えないよう、注意してお読みください。
以下、ペトロンさんの応募解答+私のコメントになります。
Challenge CVE-2020-13777(MITM, 0-RTT Application dataの復元)
この解説文章・PoCの目的
(省略)
免責事項
(省略)
はじめに
(省略)
CVE-2020-13777について
(省略)
次のセクションでTLS1.3における影響について説明します。
1. TLS1.3でのMITM攻撃について
次の1つめの課題の解答をする章です。
- pcap中のTLS1.3 ClientHelloデータだけ使って、CVE-2020-13777によってTLS1.3のMITMが可能であることを証明してください。
(コメント)
この課題を考える時、「ClientHelloデータだけ」と書いていいかどうかすごく悩みました。実は不備があるからです。ペトロンさんから、今回の省略している部分(POCコード)の説明で、この条件の不備をちゃんと指摘されてました。
このPoCの範囲外 - CipherSuiteの推定 - 簡単のため、攻撃者は1回目のCHLOのCipher Suitesのリストを見て先頭にあるTLS_AES_256_GCM_SHA384をサーバーが選択したと推定した仮定でハードコーディングしている
はい、CipherSuiteの推定が必要です。ClientHello だけでは、どのCipherSuiteを使った/使うのかわかりません。resumption PSKによる再接続では少なくとも前回の接続でのCipherSuiteのHASHがわかっていないと鍵の導出がで きないのです。本来ならServerHelloの情報も含めてと書くのが正確な課題の出し方です。
しかし、そもそもこんな「ClientHelloだけ」という不正確な条件をつけたのか。理由は、課題2を解いたことで課題1の証明するような応募を避けたかったことと、何をもって証明したとして見なせばいいのか、PSK認証の本質と私が考えていることについて述べてほしかったからです。後半の理由は後ほど詳細に書きます。
(コメント終)
PSKを使った認証
セッション再開におけるPSK(PreShared Key)はサーバーがクライアントを認証するための値です。 また、HandShakeやアプリケーションデータを暗号化/復号するための鍵のシードのようなものとしても利用されます。 PSKはexternal-PSKとresumption-PSKの二種類があり、PSKの共有方法によって分類されています。 external-PSKはTLSの帯域以外(つまり他の手段で)共有されるPSKです。 一方で、resumption-PSKは前回のセッションで用いたPSKです。セッション再開の認証に使うPSK候補が複数ある場合はサーバーからのNewSessionTicketの通知の際に次回のセッション再開と鍵の導出で使用するPSKと対応するPSK-IDが通知されます。クライアントはセッション再開時はPSK-IDに従って鍵の導出に使用するPSKを選択します。 今回はresumption-PSKを使った場合を例に説明します。以後は特に断りがない場合はPSKと書いてあるものはresumption-PSKと読み替えてください。
(コメント)
PSKについての説明です。内容は全く問題ありません。もう少し視野を上げてTLS1.3のハンドシェイクの種類で接続を分類すると下図のようになります。

TLS1.3には、大きくフルハンドシェイクとPSK接続の2種類のハンドシェイクが使われていると考えていいでしょう。正確には最初のハンドシェイクで鍵交換に失敗して2-RTTの接続してしまうハンドシェイク(Incorrect DHE Share)があります。しかし今回はわかりにくくなるので除きます。
フルハンドシェイクは、サーバ認証が必須です。通常はX.509証明書と秘密鍵を用いて認証を行います。クライアント認証も行えますがオプション扱いです(今回の図からは除いています)。
一方PSK接続の方は、応募解答に書いてある通り external PSK と resumption PSKの2つに別れます。external の方は「帯域外(out of bound)」での共有です。こういう意味での out of bound の和訳って困ってしまいますよね。私はそのままにしています。なお external PSKについては、既にプロトコル上の脆弱性が見つかっております。利用する場合には注意が必要であることをお忘れなく。
resumption PSKの方は、応募解答に書いてあるとおり前回のハンドシェイクを基にPSKを共有する方式です。実はresumption PSKにも stateful と stateless の2種類あります。
statefull resumption PSKは、セッションIDをTicketに含め、セションデータはサーバ側で保持する方式です。クラスターを組んでいる場合は、複数サーバ間でセッション状態を共有しておく必要があります。TLS1.3ではセッションIDフィールドが廃止されましたが、こんなところに引っ越していたんです。
stateless resumption PSKは、セションデータを暗号化してTicketに含める方法です。今回のやり方になります。一旦クライアントにセッションデータを預けてしまうため、サーバクラスター間ではチケット内のセッションデータを復号するチケ ット鍵だけを共有しておけばいいわけです。これはTLS1.2の時代と変わりません。
少し前に知ったのですが、OpenSSL-1.1.1のTLSサーバでTLS1.3利用時にTicket無効化のオプションを設定しても、NewSessionTicketが送られてPSK接続になってしまいます。実はこの時、OpenSSLは stateful resumption PSK を使っていて、OpenSSLのメモリ内でセッシ ョンデータを保持して再接続を処理しています。本当にTicket利用を無効化したい場合は、送信するTicket数を明示的に0にするという設定をしないといけないです。
考えられるTLS1.3ハンドシェイクの形態を全部まとめると下表のように7種類になります。

ここでは細かく項目を説明しませんが、それぞれのハンドシェイク形態でやれること、セキュリティ状態が異なります。今回は3番目の statefull (* 1) stateless resumpition PSK が課題の対象となります。 (* 1 鹿野さん、間違いの指摘ありがとうございます。)
(コメント終)
セッションチケットとPSK
PSKはセッションチケットから導出可能です。これはセッションチケットの暗号化鍵が攻撃者に知られるとセッション再開の認証に必要な情報であるPSKを攻撃者が入手できることを意味します。 そして、これは攻撃者が正規のクライアントになりすますことができることを意味します。
順を追って説明します。CVE-2020-13777はサーバーが持つセッションチケットの暗号化鍵がall-0になる脆弱性です。 つまり、この脆弱性によって攻撃者はセッションチケットの暗号化鍵が0だと推測して、その内容を不正に復号することができます。 では、攻撃者がセッションチケットの内容を入手できると、どういった手順でPSKの導出をし認証のバイパスが可能になるのでしょうか。 それを明らかにするためにはまず、TLS1.3でセッションチケットの内容や認証の手順を理解する必要があります。 それでは正常時のセッションチケットを利用した認証を例に順を追って説明します。 次の図を見てください。 図中の登場人物は次のとおりです。
- Alice: 正規のTLS1.3クライアント
- Bob: 正規のTLS1.3サーバー



[図:セッション再開時のPSKによる認証]
図中の<>はセッションチケットの暗号化鍵で暗号化されたメッセージです。 図中の{}は[sender]handshake_traffic_secretで暗号化されたメッセージです。 図中の[]は[sender]application_traffic_secret_Nで暗号化されたメッセージです。
1つめの図はGnuTLSにおけるセッションチケットの書式を表しています。 そして、2つ目の図フルハンドシェイクの時の認証はフルハンドシェイクのシーケンスと認証部分の図です。図の通り、セッションチケットはサーバーからクライアントへNewSessionTicketによって通知されます。また、認証は証明書によって行われます。
(コメント)
惜しい、TLS1.3のフルハンドシェイク時の認証部分が違います。これを理解するため、サーバの秘密鍵を知らない攻撃者がTLS1.3でどこまで中間者攻撃ができるか思考実験をしてみましょう(下図)。
中間攻撃者は、平文でやり取りされるClientHello/ServerHelloを自由に書き換えることができます。それぞれの key_share拡張に入っている公開鍵情報を、中間攻撃者が作成した公開鍵に差し替えてやれば、攻撃者が生成する共有鍵をクライアント・サーバそれぞれに確立することが可能です。そのため、暗号化された EncryptedExtension や Certificate は中間攻撃者に筒抜けです。暗号化されているから認証されているわけではありません。
しかしCertificateVerifyまで来たら事情が異なります。中間攻撃者はサーバの秘密鍵を持っていないので、サーバ証明書の公開鍵に応じたハンドシェイク署名(CertificateVerify)を作成できないのです。勝手な秘密鍵でCertificateVerifyを偽造したとしても、クライアントは証明書の公開鍵を使って署名検証するため検証エラーになります。中間攻撃者はここでジエンドです。

中間攻撃者は暗号化された証明書を見れるのだから、中間攻撃者が証明書自体を改ざんしたらどうなるでしょうか? なりすまし用に作成した公開鍵に入れ替えてやれば、CertificateVerifyにあるハンドシェイク署名データの偽造できるかもしれません。
残念ながら、サーバ証明書がトラストアンカー(ルート証明書)を起点として電子署名がされているので、クライアント側で証明書の改ざんがチェックされエラーになります。認証局システムを破って不正なサーバ証明書を発行しない限り無理な話です。

なのでTLS1.3のフルハンドシェイク時の認証は、上図の範囲(Certificate, CertificateVerify, Finished)になります。
(コメント終)
そして3つ目の図セッション再開時のPSKによる認証はセッション再開時のシーケンスと認証部分の図です。クライアントはセッションを再開するタイミングでセッションチケットを送信します。そして、サーバーが受け取ったセッションチケットはセッシ ョンの再開の認証に使われます。 サーバーがセッションチケットの情報を受け取るとチケットの情報とサーバーが保持している情報を基にクライアントを認証し、認証が成功するとセッションを再開します。なお、PSKによるセッション再開時の認証が成功した場合、証明書による認証は行われません。
より具体的な説明をします。まず、図GnuTLSのチケット書式の右側の"GnuTLSのチケットデータの中身の書式"を見てください。 サーバーは上から5つ目の項目のresumption_master_secretと7つ目の項目のnonceがあります。サーバーはこれらをHKDF-Expand-Label関数(※1)に入力してPSK(PreShared Key)を生成します。
psk=HKDF-Expand-Label(resumption_master_secret,
"resumption", nonce, Hash.length)
参考:RFC8446 4.6.1 https://tools.ietf.org/html/rfc8446#page-75 を基に作成
サーバーは上記の式でセッションチケットからpskを導出した後にbinder値(※2)を計算して、PSKを検証した後に自身が手元に持っているpskのリストと照らし合わせてpskがリストに存在するか、最初にこのpskが生成されてから規定以上の時間が経っていないかをチェックすることで認証を行います。
※1 HKDF-Expand-Labelは一方向性の性質を持つ鍵導出関数です。詳細については割愛しますが、出力から入力を導出できないことを覚えておいてください。 一方向性については後に登場するHKDF-Extractなど今回の説明で登場するHKDF-xxxという関数やderive_secretについても同様です。HKDFの仕様についてはRFC5869を参照してください https://tools.ietf.org/html/rfc5869
※2 簡単のため、binder値の計算については省略します。PoCに実装してありますので、興味のあるかたはそちらを参照してください。
(コメント)
「簡単のため、binder値の計算については省略します。」
くぅぅ、惜しい。自分としては、ここでbinder値を絶対に計算して欲しかったです。binder値こそがPSK認証の要の一つなんです。
まず、ここで実際にPSKの中身はどうなっているのか wireshark で見てみましょう。

四角で囲った部分がPSK拡張です。これはClientHelloの一番最後に配置されてないといけません(理由は後述)。 PSK拡張の中は、PSK Identity と PSK Binders で構成されています。PSK Identity は Identity と Obfuscated Ticket Age(難読化されたチケット経過時間) の2つが含まれています。Identityには、resumption PSKでは ticket そのものが入ります。
チケット経過時間がなぜ難読化されているのか? ClientHelloは平文であるため、チケットの経過時間が外部からわかるとその情報を使って色々いたずらされる可能性が出てきます。そのためクライアントは、チケットの経過時間にサーバから送られた難読化のための数値(ticket_age_add)を追加して、外から実際の経過時間がわからないように対策します。
PSK binders は、ClientHelloのハンドシェイクデータの先頭からPSK Binderの直前までのデータ(Truncated ClientHello)のハッシュ値を使います。このデータを resumption_master_secret から導き出した binder_key を使って Finished と同じような形でHMACした値です。
bindersの役割は2つあります。まずクライアントとサーバで同じ resumption_master_secret を持っていることを確認することです。もう一つは、Truncated ClientHelloが改ざんされていないことを保証することです。PSK拡張がClientHelloの一番最後に配置されないといけないのは、binderによるClientHelloの改ざん検知を最大限の範囲にするために必要な条件だからです。
新規接続のフルハンドシェイクからの流れを図示したのが下図です。

サーバは、PSKを持つClientHelloを受け取ったら、
1. まずPSK identityを復号し、ticket データからセッションデータや resumption_master_secret を取得します。
2. Obfuscated Ticket Ageの難読化を解き、チケットの経過時間を取得します。そして、NewSessionTicket中で規定したチケットの有効期限内かどうかチェックします。
3. クライアントと同じ方法で resumption_master_secret から binder_key を導出します。
4. サーバ側で Truncated ClientHello のデータと binder_secret からbinder値を計算します。
5. クライアントから送られてきた binder値とサーバが計算したbinder値が一致していれば、双方同じ resumption_master_secret を事前に共有していた相手であると確認したこととなり、認証が終わります。
このように binder によるMAC検証は、PSK認証を行う大きな要素の一つだということがわかるでしょう。
(コメント終)
MITM攻撃の手順を考える
この節では攻撃者がTLS1.3を使っている架空のシステムに対してCVE-2020-13777を使い、MITM攻撃(中間者攻撃)をする場合の手順を考えます。 前の節でPSKを用いたセッション再開時の認証のおおまかな流れについて説明しました。 MITM攻撃行うためには暗号化された通信の内容を復号して再度暗号化する必要があります。 つまり、攻撃者が攻撃を成功させるには鍵の導出や合意に必要な情報を持っている必要があります。 次の図を見てください。
 図:TLS1.3のKey Scheduling
図:TLS1.3のKey Scheduling
図の引用元: RFC8446 7.1 https://tools.ietf.org/html/rfc8446#page-93
この図はTLS1.3のKey Schedulingを表しています。 図の左上に着目してください。PSKと書いてあります。つまり、PSKを持っているとTLSのearly dataの暗号化/復号に必要なkey, ivを導出するための秘密情報(Secret)が手に入ります。
(コメント)
この HKDF をベースとした TLS1.3 の鍵スケジュールは、TLS1.2から一番進化したところです。この部分もいろいろコメントしたい部分がありますが、これ以上分量を増やすのもなんなんで、やめておきます。またの機会に。
(コメント終)
ハンドシェイクやアプリケーションデータを暗号化/復号するkey, ivの導出はどうすればよいでしょうか。 key, ivを導出する式を次に示します。
[sender]_write_key = HKDF-Expand-Label(Secret, "key", "", key_length) [sender]_write_iv = HKDF-Expand-Label(Secret, "iv", "", iv_length)
式:暗号化/復号 key, ivの導出
引用: RFC8446 7.3 https://tools.ietf.org/html/rfc8446#section-7.3
[sender]はデータを暗号化して送信する側を示していて、clientかserverが入ります。Secretには暗号化対象のデータ種別に対応するtraffic secretを入れます。 具体的なSecretの例を3つ紹介します。
- 送信側がクライアント, 受信側がサーバーでearly data(0-RTT Application Data)の暗号化, 復号を行う場合
- client_early_traffic_secret から導出したkey, ivを選択
- 送信側がクライアント, 受信側がサーバーでハンドシェイクの暗号化, 復号を行う場合
- client_handshake_traffic_secret から導出したkey, ivを選択
- 送信側がサーバー, 受信側がクライアントでアプリケーションの暗号化, 復号を行う場合
- server_application_traffic_secret_N から導出したkey, ivを選択
なお、KeySchedulingの図について、[sender]handshake_traffic_secret, [sender]application_traffic_secretの導出に着目すると、 これらの導出には(EC)DHEの共有鍵が必要なことがわかります。攻撃者は(EC)DHEへの中間者攻撃を行うことで(EC)DHEの共有鍵を手に入れることができます。
ここまでの流れをまとめると次の図のように攻撃できます。 図中の登場人物は次のとおりです。 なお、前提としてAliceはセッション再開以前にCVE-2020-13777の脆弱性を持っているBobをやりとりをしていて、PSKを用いてセッションの再開を試みているものとします。
- Alice: 正規のTLS1.3クライアント
- Bob: 正規のTLS1.3サーバー(ただし、CVE-2020-13777の脆弱性を持っている)
- Mallory: MITM攻撃を行う攻撃者

RFC 8446 2.3節より、 PSKでの認証時はサーバーは証明書による認証を行ないません。 そのため、認証のバイパスに成功するとそれ以後、Malloryは[sender/receiver]handshake_traffic_secretや [sender/receiver]application_traffic_secret_N を用いて鍵やivを導出し、ハンドシェイクやApplication Dataの暗号化/復号ができるため、MITM攻撃が成立します。また、PSKの導出にはセッション再開時のCHLOのみを使っているので設問の要件「ClientHelloデータだけ使って」という要件を満たします。
(コメント)
MITM攻撃の手順は上記の通りで問題ありません。resumption_master_secretから導出したPSKを攻撃者が作成できれば、芋づる式にTLS1.3で利用する各種暗号鍵を生成できることとなり、PSK接続のハンドシェイクを自由に盗聴・ 改ざんし、成りすましもできるようになります。
ただ惜しむらくは、binderのチェックを省略せず入れて欲しかったぁ。
今回Ticketデータの書式を課題で提示しましたが、もし間違ったオフセットで resumption_master_secret を抽出していたり、(今回の課題の仮定の範囲外ですが)書式自体の間違いや更新などがあったら、MITMが成功しません。中間攻撃者がMITMを確実に成功させるには、ClientHelloを受信した時点で中間攻撃者自身がbinderの計算を行い一致するかどうかを確認するのが一番確実です。
中間攻撃者は、binder値の一致をもって、PSK Identityから解読したクライアント・サーバ間で事前共有されている resumption_master_secret が入手できたと初めて客観的に証明できるわけです。それが「ClientHelloデー タだけ」 という指定を入れた意図でしたが、やっぱり意図通りに課題を作るのは難しいと実感しました。これは出題者の力不足です。
ただ binder値のチェックはちゃんとPOCにも入っていますし、PSK生成からのMITMの手順も間違っていないのでこの解答を正解とみなしたいと思います。
(コメント終)
2. 0-RTT Application dataの復号
次の2つめの課題の解答をする章です。
- pcap中の暗号化されたTLS1.3 の 0-RTTアプリケーションデータをCVE-2020-13777によって復号し、アプリケーションデータの平文を取得してください。
PSKを導出するまでは1と同じです。説明とPoCを次に示します。なお、PoCの実装に際して
これらをコードの実装のヒントとして利用しました。 PoCの方針は次の図0-RTT Application dataの復元の通りです。 図中の登場人物は次のとおりです。 前提として、これまでと同様にAliceはセッション再開以前にCVE-2020-13777の脆弱性を持っているBobをやりとりをしていて、PSKを用いてセッションの再開を試みているものとします。
- Alice: 正規のTLS1.3クライアント
- Bob: 正規のTLS1.3クライアント(ただし、CVE-2020-13777の脆弱性を持っている)
- Eve: Aliceのパケットを盗聴し、CHLOのApplication dataを不正に復元しようとする攻撃者
PSK導出後、Key SchedulingにしたがってPSKからclient_early_traffic_secureを導出します。 次にclient_early_traffic_secureからkeyとivを導出(※3)し、nonce=iv xor packet_number(=0, ApplicationDataはCHLOパケットに含まれているため)(※4)を算出します。
(コメント)
IVの生成もTLS1.2が大きく変わった点です。TLS1.2まではIVは明示的に生成してTLSレコードにつけていましたが、TLS1.3ではそれが必要なくなりました。これによってIVの再利用のリスクを無くすこともでき、IV分のデータ長も節約できることになりました。
(コメント終)
最後に復号をします。
暗号アルゴリズムは初回のセッションのCHLOのCipherSuitesのリストの最上位がCipher Suite: TLS_AES_256_GCM_SHA384 (0x1302)であることからAESのGCMモードで鍵長32byte, nonce12byte, MACの長さが16byteであると推定します。
AEADのassociateは(Early dataが入っているTLSレコードレイヤーのヘッダ+暗号文の長さ)であるのがGnuTLSや他のTLS実装のソースコードにより判明したためそれを利用します。
(コメント)
AEADで改ざん検知を行うAssociate Data部分にはTLSレコードレイヤが入りますが、TLS1.3ではこの部分は改ざんされても問題ないので特に入れ込む必要がないデータです。ただ形式証明を行う場合に入っていないと正確な分析ができないということで入れ込むことになりました。透過性の問題さえなければレコードレイヤー自体必要のない無駄なデータなんです。
(コメント終)
最後に末尾16byteをMACとして切り出し、残りを暗号文として復号関数に入力します。

ここまでの説明した方針に沿って実装したPoCを実行した結果を示します。 復元したApplication dataの平文をASCIIと16進数文字列で表示した結果は次の通りです。 また、PoCのコードはこの記事の末尾にあります。
$python3 main.py b"Let's study TLS with Professional SSL/TLS!\n\n\x17" 4c6574277320737475647920544c5320776974682050726f66657373696f6e616c2053534c2f544c53210a0a17
図:PoCの実行結果
(コメント)
お見事! 正解は、「Let's study TLS with Professional SSL/TLS!\n\n」でした。最後の0x17は、Application の Content-Type (23) が入ったものなのでちょっと余分ですが、問題ないです。
このように、TLS1.3では 0-RTT で送信されるデータの Forward Secrecy は確保できません。Ticket鍵が漏洩すれば、後日保管しておいたpcapファイル中の暗号データから平文データを解読できます。
しかしハンドシェイク後に送受信されたアプリケーションデータのForward Secrecyは守れます。これは、PSK接続では PSKと(EC)DHEを組み合わせたハイブリットモードを用意しています。psk_key_exchange_mode拡張で psk_dhe_ke が指定されている場合にPSK/(EC)DHEのハイブリッドで鍵交換されます。
下図の通り、0-RTTのデータは(EC)DHEとハイブリッド鍵交換する前の鍵で暗号化されるので Forward Securityはないですが、ハンドシェイク後のアプリケーションデータは、PSKと(EC)DHEのハイブリッド鍵交換後に導出された暗号鍵で守られています。

(EC)DHEは再接続時に一時的に生成されるものなのですぐ消去することができます。攻撃者がresumption_master_secretを入手してPSKを導出しようと、再接続時の一時鍵(EC)DHEがわからなければアプリケーションデータの暗号鍵を導出することは不可能だからです。
(コメント終)
自身でPoCを実行して結果を確認するには下記のリンクからChallenge CVE-2020-13777のpcapファイルをダウンロードし、次に示すディレクトリの構成を参考にPoCの実行ファイル(ファイル名:main.py)をpcapファイルと同じ階層に配置してください。
(コメント)
以下PoCコードの説明が続きますが、省略します。続きは、オリジナルの応募解答か、ペロトンさんのブログを参照してください。
(コメント終)
(コメントまとめ)
いろいろ難癖つけてる感じに読めますが、短期間で見事な解答だと思います。ちょうど解答が「Let's study TLS with Professional SSL/TLS!」でペロトンさんもプロフェッショナルSSL/TLSをお持ちでないということでVさんからの副賞はプロフェッショナルSSL/TLSになりました。
十分本の内容を理解できる実力をお持ちだと思うので、しっかり読み込んでいただきたいと思います。
課題に取り組んでいただいた皆さん、ありがとうございました。
(コメントまとめ終)
求む!TLS1.3の再接続を完全に理解した方(Challenge CVE-2020-13777)
1. GnuTLSの深刻な脆弱性(CVE-2020-13777)
先日、GnuTLSで深刻な脆弱性が見つかりました。
GNUTLS-SA-2020-06-03: CVE-2020-13777
It was found that GnuTLS 3.6.4 introduced a regression in the TLS protocol implementation.
This caused the TLS server to not securely construct a session ticket encryption key considering the application supplied secret, allowing a MitM attacker to bypass authentication in TLS 1.3 and recover previous conversations in TLS 1.2.
See #1011 for more discussion on the topic.
Recommendation: To address the issue found upgrade to GnuTLS 3.6.14 or later versions.
.
GnuTLS 3.6.4では、TLSプロトコルの実装にリグレッションが入っていることが判明しました。
これによりTLS サーバは、アプリケーションから渡された秘密鍵を使ってセッションチケットを暗号化する鍵が安全に生成されませんでした。
TLS 1.3では中間攻撃者が認証をバイパスすることができます。TLS 1.2では過去の通信を復号することができます。
このトピックに関する詳細な議論は、#1011を参照してください。
推奨: 発見された問題に対処するには、GnuTLS 3.6.14 以降のバージョンにアップグレードしてください。
issueを見ると、なんと stateless なTLS再接続を実現するTLSのセッションチケット情報が、TLSサーバ立ち上がりの数時間はオール0の暗号鍵で暗号化されていたというバグでした。
2年近く前、チケットの暗号鍵にTOTP(Time-Based One-Time Password Algorithm)のような機能を導入し、暗号鍵が定期的に変わるように変更したようなのですが、その際初期化のところでバグが入っていたようです。
これはなかなか衝撃的で痺れる脆弱性です。脆弱性に該当するバージョンを利用している方は直ちにアップデートしてください。
TLSセッションチケットの中身を守ることは、TLS通信の安全性を確保する要の一つです。脆弱性対象のGnuTLSを利用している全てのTLSサーバで、このチケットを暗号化する鍵が危殆化してしまったのですからそりゃ大変です。
ネット上では、このTOTPは意味はないのに入れちゃって、かえって致命的なバグを混入させたとして、GnuTLSに対する信頼性について批判するような意見も見受けられています。
issue見ると、日本人の名前の方がGnuTLSのメンテをされているようです。大変なご苦労かと思います。 ここではGnuTLSがどうだこうだと言うつもりはなく、純粋に技術的な観点からこの脆弱性の影響について考えてみたいと思っています。
2.ものは試し Challenge CVE-2020-13777
この脆弱性、実際にPoCを書いてみると非常に奥が深いです。TLS 1.3をちゃんと理解していないと無理です。
TLS 1.2 と TLS 1.3 でなぜ影響に違いがあるのか、そこはTLS 1.3の進化が見えるところです。またアナウンスには記述されていませんが、TLS 1.3の0-RTTを利用していた場合、この脆弱性によって大きな影響が新しく出てきます。
さっそく「GnuTLSの脆弱性(CVE-2020-13777)でTLS1.3の再接続を完全に理解する」というタイトルでブログを書こうと思いましたが、いつもの通りでは面白くない。なんか良からぬ考えが頭をよぎりました。
これ、どのぐらいの方が理解されるのでしょうか? 一度問題を作って、回答を公募してみようと思います。
3. 問題
以下のレポジトリにある pcap データを使って次の問題1,2に回答してください。
pcap データにはGnuTLS-3.6.13のサーバ(192.168.100.23:5556)に対するTLS1.3の接続データが2つ含まれています。1回目は新規TLS1.3接続、続く2回目は 0-RTT のTLS1.3再接続です。
https://github.com/shigeki/challenge_CVE-2020-13777
- pcap中のTLS1.3 ClientHelloデータだけ使って、CVE-2020-13777によってTLS1.3のMITMが可能であることを証明してください。
- pcap中の暗号化されたTLS1.3 の 0-RTTアプリケーションデータをCVE-2020-13777によって復号し、アプリケーションデータの平文を取得してください。
できるだけ純粋にTLS1.3仕様の理解を実証していただくため、GnuTLS固有で必要な情報(暗号化されたチケットの書式、チケットの中身の書式)は以下にヒントとして記しておきます。

不明な点は、直接GnuTLSのソースコードを参照してください。
4. 応募方法、期限
回答の説明と回答を得るために使ったソースコード を secret gist にあげて、そのリンクを私(twitter:@jovi0608)までDMで送ってください。
2問回答された方で、私の判断で一番見事と思う回答者1名にアマゾンギフト券(1万円)を贈呈したいと思います。
対象者が複数いた場合は、応募時間が先の方に贈呈します。
4.1 Vさん賞贈呈の追記 (6/13 13:40)
急遽Vさん賞を別途設けます。Vさんが好みそうな方を独自に選んでギフト贈呈します。
"贈呈するギフト券は完全に自分のポケットマネーです。これを機にTLS1.3仕様の完全理解に取り組んでくれる方がいらっしゃれば嬉しいです" 自分もポケットマネーで +1 万円のアマゾンギフト出したいw(まつりにのっかりたいだけ) https://t.co/pWJUVUxmMU
— V (@voluntas) 2020年6月13日
応募期限は、2020年6月18日(木) 23時59分59秒(JST) です。
5. 応募条件、免責事項
応募条件は、細かいですが以下の方でお願いします。
- 「TLS1.3やQUICの実装していて、他者に提供している人」でない方:(実装されてる方は完全に理解されてますよねw 自己申告に任せます)。(追記6/13 11:24, ちょっと書き方が紛らわしかったので少し明確にしました。)
- 正解の有無に関わらず、応募された twitter/githubアカウントや応募内容について、このブログで公開を許可していただける方(内容によっては文意を変えない程度に編集をさせていただきます)。
- なにかリーガル上の理由やその他考慮不足など止む得ない理由で、予告なく Challenge の条件変更や取りやめを行う可能性がありますが、ご了承いただける方。
- 私の一存の判断で応募内容の評価させていただくことに異論のない方。
TLS 1.2のPoCに関しては、全てのアプリケーションデータの forward secrecy を破ることになり影響が大きいので対象としません。
TLS 1.3については、現在 0-RTT を利用していると公表している中で netflix が一番の大規模サービスと思いますが、今回の脆弱性に該当するGnuTLSを利用していないことを確認済です。TLS1.3 0-RTTの機能はセキュリティ上の理由で安全に利用するのが難しく現在利用が普及していません。そのため今回のPoC公開・解説はあまり世間に影響ないものと判断しています。もし影響が大きいとわかれば、PoCの公表を取りやめます。
こういうことやるの初めてなので、いろんな不備・不測の自体が発生した場合にはお許しください。なにか不明な点があればこのブログにコメントください(moderateされています)。
応募が全然なかったら寂しいですね。贈呈するギフト券は完全に自分のポケットマネーです。これを機にTLS1.3仕様の完全理解に取り組んでくれる方がいらっしゃれば嬉しいです。
TLS1.3の再接続を完全に理解している方、応募をお待ちしています!
Let's EncryptがはまったGolangの落とし穴
0. 短いまとめ
300万以上の証明書の失効を迫られたLet's Encryptのインシデントは「Golangでよくある間違い」と書かれているようなバグが原因でした。
1. はじめに、
Let's Encryptは、無料でサーバ証明書を自動化して発行するサービスを行う非営利団体として2014年に設立されました。
2015年にサービス開始されると証明書の発行数はぐんぐん伸び、先月末のプレスリリースでは累計10億枚のサーバ証明書を発行したことがアナウンスされました「Let's Encrypt Has Issued a Billion Certificates」。CTLogの調査から、2020年2月末の時点では有効な全証明書の38.4%がLet's Encryptの証明書であるとみられています「Certificate Validity Dates」。
無料の証明書を提供してもらえるのは非常に嬉しいのですが、認証局の業務やシステムの運用には当然大きなコストが掛かります。私も正式公開前のベータサービスの時から個人ドメインでLet's Encryptの証明書を利用し始めましたが、はたして寄付金だけを頼り、非営利で無料のままこのようなサービスを長期に継続して提供できるのだろうか?
正直言ってこのプロジェクトを初めて聞いた時 Let's Encrypt の先行きに少し不安を持っていました。もしくは将来、有料のEV証明書とかをきっと売り始めるだろうとも予想していました。
それからもう4年半も経ちました。Let's Encryptが主体となってドメイン認証と証明書発行の自動化を行うACME(Automatic Certificate Management Environment)プロトコルの仕様化も完了し、現在はACME v2が運用中です。 これによってDV証明書限定になりますが、従来の認証局が積極的に進めようとしなかった証明書発行システムの完全自動化に成功し、現在わずか13名のフルタイムスタッフと年間USD3.35M(約3億5千万円)の予算でLet's Encryptのシステムが運用され、大規模な証明書発行サービスを実現できています。本当に驚きです。
日本企業からは、時雨堂さん・さくらインターネットさんなどがLet's Encryptのスポンサーとして貢献されています。もうホント感謝しかありません。
Let's Encryptは間違いなく世界のWebサービスのHTTPS化を大きく進めたもの思います。
しかしこういった高い貢献に対する評価の反面、Let's Encryptによって無料証明書を使ったHTTPSのフィッシングサイトが大幅に増加しているといった負の側面も指摘されています。
これはLet's Encryptだけが悪いとは思いません。結局Web PKIをめぐる歴史的経緯の中で生まれた様々な歪がLet's Encryptによって今あぶり出されたものだと私は思っています。
2. Let's Encryptのインシデント
そんな今では世界1位のシェアを持つLet's Encryptですが、先日証明書発行に関するインシデント発生のアナウンスがCommunity Supportに投稿されました「2020.02.29 CAA Rechecking Bug」。 Mozillaには「Let's Encrypt: CAA Rechecking bug」のチケットで報告されています。
この報告によると、Let's Encryptがgithub上で開発を続けている認証システム boulder でバグが見つかり、一部の証明書でドメインのCAA(Certification Authority Authorization)を再チェックせずに発行してしまったとのこと。
証明書の発行の際に記載ドメインすべてのCAAレコードをチェックすることは、CA/Browser Forum のBR(Baseline Requirements)を基としたLet's EncryptのCP(Certificate Policy)に規定されており、証明書発行時の必須要件です。
この規定要件に反して証明書発行が行われた場合、以下のCP規定に従い5日以内に対象の証明書を失効させなければなりません。
4.9.1.1 Reasons for revoking a subscriber certificate
The CA SHOULD revoke a certificate within 24 hours and MUST revoke a Certificate within 5 days if one or more of the following occurs:
7. The CA is made aware that the Certificate was not issued in accordance with these Requirements or the CA's Certificate Policy or Certification Practice Statement;4.9.1.1 加入者の証明書を取り消す理由
CAは次のインシデントが1つ以上が発生した場合、24時間以内に証明書を取り消すべきであり(SHOULD)、5日以内に証明書を取り消さなければなりません(MUST)。
7. 証明書がここに記載されている要件またはCAの証明書ポリシー・認証実施規定に従って発行されていないことをCAが認識した時
証明書の失効方針とユーザへ証明書の再発行をメールで要請したことについて、「Revoking certain certificates on March 4」 のアナウンスも直ちに投稿されました。
対象となったのはおよそ305万の証明書、Let's Encryptから発行済みで有効な証明書のおよそ2.8%にあたる多さです。これをインシデント発見から5日以内、2020年3月5日3:00(UTC)までに全部失効させなければなりません。
Let's Encryptからの要請を受け、この期限日までにユーザによって170万以上の証明書が再発行されました。
しかしまだ130万証明書証明書が未更新のままで、その半数以上(約65%)が現在利用中であることがわかりました。このまま稼働中の証明書を強制的に失効させると、多数のWebサービスに重大な影響を与えることが予想されます。
結局、Let's Encryptはその影響度を考慮し、CP規定の5日以内に未更新の証明書を失効させることを止め、残り83日のExpireを待つ方針としました。引き続き証明書モニターと連絡を継続。今後この様な大規模インシデントに対応できるよう、失効通知するプロトコルの開発を進めるということです「Let's Encrypt: Incomplete revocation for CAA rechecking bug」。
この方針に対して各ブラウザーベンダーが今後どう反応するのか、気になるところです。
今回のインシデントは、Go言語で開発されているboulderのバグによるものです。このバグの詳細についてIncident Reportで細かく言及されていました。
このレポートを読んでみると、驚いたことにこのバグは、GoのWikiページで「CommonMistakes/Using reference to loop iterator variable(よくある間違い/iterator変数をloopする際に参照を使う場合)」で書かれてある間違いが直接の原因でした。
Wikiではこの間違いを、
func main() { var out []*int for i := 0; i < 3; i++ { out = append(out, &i) } fmt.Println("Values:", *out[0], *out[1], *out[2]) fmt.Println("Addresses:", out[0], out[1], out[2]) }
のようなコードで実例として挙げています。
これは、ループ内でループ変数iの参照を配列に入れてしまうことで、ループ終了後の出力値が
$ ./test_gomistake Values: 3 3 3 Addresses: 0xc0000160a0 0xc0000160a0 0xc0000160a0
のように配列が全て同じ値になってしまう問題です。
for や range などで扱うループ変数が同じ参照になることを知っていないとやってしまいそうな初心者的な間違いです。
しかし実際にboulderコードを読むと、Let's Encryptのエンジニアは決してこの間違いを知らなかったわけではなく、ある変数ではきちんと対応していたのに他の変数ではうっかりこの間違いを見逃してしまったことが原因のようでした。
これはひょっとしたら自分もいつかこのようなバグを仕込んでしまうかも、と背筋が寒くなりました。
今回、300万以上の証明書を失効させるほどの要因となったCAAとはどういうものなのか? なぜ再チェックが必要なのか? このGoではよくある問題と書かれている程のバグは、なぜどのように発生したのか? について、このブログでまとめてみたいと思います。
3. CAAとはなにか?
CAA(Certification Authority Authorization)は、ドメインの管理者がDNSレコードに証明書発行を許可する認証局情報を記載し、証明書の不正発行や誤発行を防ぐ技術です。
認証局による証明書の誤発行や不正発行が問題となった2013年にRFC6844でCAAの仕様化が行われました。2019年11月に探索アルゴリズムのバグ修正をした改訂版RFC8659が発行されています。
ブラウザベンダや認証局が参加するCA/Browser Forumの規約で2017年9月よりCAAがサポートすることが必須化されました。この規定により、証明書発行する際には必ずCAAレコードのチェックが入ります。
認証局は、証明書発行時に証明書の subjectAltName フィールドに記載されている全てのドメインに対してCAAのチェックを行わなければなりません。
CAAレコードに記載されているドメインが自社指定のものであるなら証明書を発行することができますが、そうでなければ発行せずエラーを返します。
だからと言って焦ってドメインにCAAレコードを追加する必要はありません。CAAレコードの登録自体はオプション扱いです。CAAレコードが引けなかった場合でも証明書は発行されます。 「CAAレコードが設定されておらず、存在しなかった場合も証明書は発行されます。」
2020年3月9日18:00更新 DNSエラー時のCAAチェックについて
Yasuhiro Morishita (@OrangeMorishita) | TwitterさんよりDNSエラー時の説明が間違っていることを指摘していただきました。ご指摘の通りですので記載内容を取り消しました。
(続き)ですので、細かいですが当該部分を「CAAレコードが設定されておらず、存在しなかった場合も証明書は発行されます。」とされる方が、よいのではないかと思いました。
— Yasuhiro Morishita (@OrangeMorishita) 2020年3月9日
この辺、私が規定を読み間違え、コードの確認も怠っていました。詳細については以下のtogetterをご確認ください。 ご指摘本当に感謝いたします。 togetter.com
次の図では、普段 example.com ドメインが認証局1(ca1.example.net)から証明書発行を受けている場合を例にします。
 example.com のドメイン管理者は、DNSサーバに ca1.example.net のCAAレコードを登録し、認証局1から証明書の発行が可能であることを示しておきます。
example.com のドメイン管理者は、DNSサーバに ca1.example.net のCAAレコードを登録し、認証局1から証明書の発行が可能であることを示しておきます。
攻撃者は、別の認証局2に対してなんらかの穴をついて www.example.com の証明書を発行しようとします。その際認証局2は、 www.example.com のCAAレコードをチェックにいきます。
CAAレコードでは www.example.com の証明書発行可能であるのは認証局1だけであることが記載されているため、認証局2では www.example.com の証明書発行要求を拒否してエラーとして返します。
よって攻撃者による www.eample.com の不正証明書入手は失敗に終わります。
CAAのレコードに記載するデータフォーマットは以下のような項目が入ります。
 例えば実際のドメインでは以下のようなCAAレコードが登録されているのがわかります。
例えば実際のドメインでは以下のようなCAAレコードが登録されているのがわかります。
 このドメインは、CyberTrust、DigiCert、GlobalSignの認証局3社からしか証明書が発行できないよう指定されているのがわかります。
このドメインは、CyberTrust、DigiCert、GlobalSignの認証局3社からしか証明書が発行できないよう指定されているのがわかります。
SSL Labs の統計では、2020年3月3日時点で7.1%のサイトがCAAの設定をしていると報告されています。やはりオプション扱いなので、まだそれほど高い普及率とは言えません。
CAAで証明書の不正発行や誤発行をすべて防ぐことはできません。むしろ限定されたケースでしかCAAによって守ることはできないと言っていいでしょう。
例えば、認証局システムのCAAチェックを無効化するまで完全に乗っ取られたり、(DNSSECを利用していない場合に)DNSへの攻撃などを合わせられるようなケースに対してはCAAは無力です。
実際にCAAを設定しているのにドメインレジストラへの攻撃によって証明書の不正発行防げなかった事例がありました。
Googleのドメインには自社認証局 pki.goog の CAA が設定されていますが、2017年にGoogleのtg(トーゴ)ドメイン(google.tg)がLet's Encryptから不正発行が発覚しています。
https://crt.sh/?id=245397170
 この証明書は直ちに失効されました。
この証明書は直ちに失効されました。
RFCではアプリケーションがCAAレコードを参照して証明書を検証することを禁止しています。そのためCAAレコードを付与することによってサービスが直接影響を受ける可能性は非常に少ないです。
サービスに与えるリスクが少なく、手軽に証明書の不正発行の対策ができることがCAAのメリットです。ただドメインにCNAMEが付与されている場合、CAAレコードの探索が少し複雑になりますので注意しましょう。
4. Let's Encryptの証明書発行を支えるboulder
boulder のアーキテクチャを下図に示します。以下 github repoのdocumentから引用した図を付けています。
 boulderのシステム要素を全て解説するわけにいきませんので、今回関連する部分だけを書きます。各システム要素(Authority)は protocol buffer v2 を使った gRPC で連携して動作しています。
boulderのシステム要素を全て解説するわけにいきませんので、今回関連する部分だけを書きます。各システム要素(Authority)は protocol buffer v2 を使った gRPC で連携して動作しています。
ACME v2 ではおおよそ以下のステップで証明書発行を行います。
- Subscriber(ユーザ or クライアント)は、letsencrypt(旧certbot)コマンド等を通じて ACME v2プロトコルを使ってWFE(Web Front End)サーバと通信します。
- ユーザ認証系が整っていればクライアントは、証明書発行のための Order をWFE経由でRA(Registration Authority)に送ります。
- http-01とかdns-01等の指定された Challenge 形式の手順に従い、RA経由でVA(Validation Authority)がユーザへのサーバにアクセスしてドメイン認証(Challenge Response)を行います。
この時VAは、発行ドメインのCAAレコードをチェックして証明書発行が許可されているかどうかを確認します。 ここで一度認証されたドメイン認証情報は、Let's Encryptの場合30日間有効です。FAQ Technical Questionには以下の通り記載されています。
ここで一度認証されたドメイン認証情報は、Let's Encryptの場合30日間有効です。FAQ Technical Questionには以下の通り記載されています。
Once you successfully complete the challenges for a domain, the resulting authorization is cached for your account to use again later. Cached authorizations last for 30 days from the time of validation. If the certificate you requested has all of the necessary authorizations cached then validation will not happen again until the relevant cached authorizations expire
ドメインに対するチャレンジが正常に完了すると、認証された結果がアカウントに対してキャッシュされ、後で再び使用できるようになります。 認証のキャッシュは検証時から30日間継続します。 発行要求した証明書が必要な認証を全てキャッシュされている場合には、その認証が期限切れになるまでvalidationは再度行われません。 - クライアントはWFEとRAを通じてCA(Certificate Authority)に証明書の発行要求(Order Final)を行います。この際ドメイン認証から8時間以上経っていればRAは再度CAAのチェックを行います。
 なぜ8時間以上経ったらRAによるCAAの再チェックが必要なのか? 実はCPの下記規定により、CAAチェック結果は最大でも8時間しか有効とみなせない規定があるからです。
なぜ8時間以上経ったらRAによるCAAの再チェックが必要なのか? 実はCPの下記規定により、CAAチェック結果は最大でも8時間しか有効とみなせない規定があるからです。
3.2.2.8. CAA Records If the CA issues, they must do so within the TTL of the CAA record, or 8 hours, whichever is greater.
CAが発行する際は、CAAレコードのTTLまたは8時間のいずれか大きい方の時間内で証明書を発行しなければならない。
ドメイン認証は30日間有効ですので、ドメイン認証から8時間後を過ぎるとその時のCAAチェック結果は無効になります。ドメイン認証から8時間後かつ30日以内で証明書発行を要求されると、ドメイン認証でのCAAチェックはスキップされるので、RAは再度CAAをチェックしないといけないわけです。
5. boulderのバグ
今回バグは、当初ユーザからエラーが99個の同一のメッセージを出しているとのレポートによって発覚しました「Rechecking caa fails with 99 identical subproblems」。100のドメインを含んだ証明書発行を要求した際に、同一ドメインのCAAのrecheckエラーが99個含まれたメッセージが返ってきたのです。
このissueに反応した別のコミュニティユーザが現象を確認し、Let's Encryptスタッフに対して以下の問いかけます。
any confirmation? (I’m wary that this might actually be possible to apply as a CAA re-checking bypass … maybe I should delete and send to security@ …)
確認できます? (これが実際にCAAの再チェックをバイパスできるかもしれないと心配しています… おそらくこれを削除して security@ に連絡すべきかもしれませんが…)
なんと聡明なユーザでしょう。ですが残念なことにLet's Encryptのスタッフは当初これをエラー表示の問題と捉えていました。しかし数日後パッチを作って確認している際に間違いであることに気づきました。
問題はRAがOrder Finalの際にCAAの再チェックを行うところです。そこではRAとSA(Storage Authority)の間のgRPCで以下のやり取りがされていました。

- RAは、クライアントからの証明書発行要求(Order Final)を受け認証情報を確認します(checkAUthorizations)。その際RAは、CSRのsubjectAltNameに記載されている各ドメインの認証情報をSAに対してgRPCを通じて入手します(GetValidAuthorizations2)。
- SAは、自身が管理している認証情報(AuthzModel)をProtocol Buffer v2形式にして、ドメインと認証情報のMapを配列に入れRAに返します(authzModelMapToPB, modelToAuthzPB)。
- RAは、その認証情報に記載されているドメイン情報を見てCAAレコードをチェックします(checkAuthorizationCAA/recheckCAA)。
バグに関連する該当部分のコード(authzModelMapToPB, modelToAuthzPB)を示します。説明がわかりやすくなるよう便宜的に行番号をふっています。また一部説明に関係ない部分のコードを省略しています。
1.func modelToAuthzPB(am *authzModel) (*corepb.Authorization, error) { 2. expires := am.Expires.UTC().UnixNano() 3. id := fmt.Sprintf("%d", am.ID) 4. status := uintToStatus[am.Status] 5 pb := &corepb.Authorization{ 6. Id: &id, 7. Status: &status, 8. Identifier: &am.IdentifierValue, 9. RegistrationID: &am.RegistrationID, 10. Expires: &expires, 11. } 12. (snip) 13. return pb, nil 14.} 15. 16. // authzModelMapToPB converts a mapping of domain name to authzModels into a 17. // protobuf authorizations map 18. func authzModelMapToPB(m map[string]authzModel) (*sapb.Authorizations, error) { 19. resp := &sapb.Authorizations{} 20. for k, v := range m { 21. // Make a copy of k because it will be reassigned with each loop. 22. kCopy := k 23. authzPB, err := modelToAuthzPB(&v) 24. if err != nil { 25. return nil, err 26. } 27. resp.Authz = append(resp.Authz, &sapb.Authorizations_MapElement{Domain: &kCopy, Authz: authzPB}) 28. } 29. return resp, nil 30.}
ありました「よくある間違い/iterator変数をloopeする際に参照を使う場合」です。20行目から28行目に渡るfor loopが該当します。
authzModelMapToPBに渡されたmap m の key k と value v を参照しています。
kに関しては、ちゃんとバグにならないよう kCopyに代入して別の参照に渡しています。
vに関しては、modelToAuthzPBに参照を渡していますが一見問題がなさそうです。でも渡されたmodelToAuthzPBにおいてIdentifierとRegistrationIDのフィールドにvの参照を渡しています。そしてその返り値を配列に代入しています。
この部分だけ切り出して動作するようにして試してみます(動作が変わらない程度に若干コードに変更をかけています)。
package main import ( "fmt" "time" apb "./proto" ) type authzModel struct { ID int64 IdentifierType uint8 IdentifierValue string RegistrationID int64 Status uint8 Expires time.Time } func modelToAuthzPB(am *authzModel) (*apb.Authorization, error) { expires := am.Expires.UTC().UnixNano() id := fmt.Sprintf("%d", am.ID) status := "valid" pb := &apb.Authorization{ Id: &id, Status: &status, Identifier: &am.IdentifierValue, RegistrationID: &am.RegistrationID, Expires: &expires, } // snip return pb, nil } func authzModelMapToPB(m map[string]authzModel) (*apb.Authorizations, error) { resp := &apb.Authorizations{} for k, v := range m { // Make a copy of k because it will be reassigned with each loop. kCopy := k authzPB, err := modelToAuthzPB(&v) if err != nil { return nil, err } resp.Authz = append(resp.Authz, &apb.Authorizations_MapElement{Domain: &kCopy, Authz: authzPB}) } return resp, nil } func main() { authzModels := [...]authzModel{ authzModel{1,1,"www.example1.com",1,1, time.Date(2020, time.January, 1, 1, 1, 1, 1, time.UTC)}, authzModel{2,2,"www.example2.com",2,2, time.Date(2020, time.February, 2, 2, 2, 2, 2, time.UTC)}, authzModel{3,3,"www.example3.com",3,3, time.Date(2020, time.March, 3, 3, 3, 3, 3, time.UTC)}, } authzModelMap := make(map[string]authzModel) for _, am := range authzModels { authzModelMap[am.IdentifierValue] = am } resp, _ := authzModelMapToPB(authzModelMap) fmt.Printf("%+v, Identifier:%p, RegistrationID:%p\n", resp.Authz[0], resp.Authz[0].Authz.Identifier, resp.Authz[0].Authz.RegistrationID) fmt.Printf("%+v, Identifier:%p, RegistrationID:%p\n", resp.Authz[1], resp.Authz[1].Authz.Identifier, resp.Authz[1].Authz.RegistrationID) fmt.Printf("%+v, Identifier:%p, RegistrationID:%p\n", resp.Authz[2], resp.Authz[2].Authz.Identifier, resp.Authz[2].Authz.RegistrationID) }
ここでは、テスト用のmapデータwww.example[1-3].comの3つのドメインを渡された場合を模擬しています。
実行してみます。
$ ./le_bug domain:"www.example1.com" authz:<id:"1" identifier:"www.example3.com" registrationID:3 status:"valid" expires:1577840461000000001 > , Identifier:0xc0000c8060, RegistrationID:0xc0000c8070 domain:"www.example2.com" authz:<id:"2" identifier:"www.example3.com" registrationID:3 status:"valid" expires:1580608922000000002 > , Identifier:0xc0000c8060, RegistrationID:0xc0000c8070 domain:"www.example3.com" authz:<id:"3" identifier:"www.example3.com" registrationID:3 status:"valid" expires:1583204583000000003 > , Identifier:0xc0000c8060, RegistrationID:0xc0000c8070
あぁ、identifier と registrationIDは同じ参照になっているため同じ値(www.example3.com, 3)になっています。recheckCAAはregistrationIDを参照するため、これではwww.example3.comの1ドメインしかCAAの再チェックを行いません。バグが再現できました。
このバグは、次のPR(Pass authzModel by value, not reference)で修正されました。単純に参照渡しを値渡しに変えるだけです。ここでも同じ修正をしてみます。
diff --git a/main.go b/main.go index e4fa2a1..828401d 100644 --- a/main.go +++ b/main.go @@ -15,7 +15,7 @@ type authzModel struct { Expires time.Time } -func modelToAuthzPB(am *authzModel) (*apb.Authorization, error) { +func modelToAuthzPB(am authzModel) (*apb.Authorization, error) { expires := am.Expires.UTC().UnixNano() id := fmt.Sprintf("%d", am.ID) status := "valid" @@ -36,7 +36,7 @@ func authzModelMapToPB(m map[string]authzModel) (*apb.Authorizations, error) { for k, v := range m { // Make a copy of k because it will be reassigned with each loop. kCopy := k - authzPB, err := modelToAuthzPB(&v) + authzPB, err := modelToAuthzPB(v) if err != nil { return nil, err }
試してみましょう。
$ ./le_bug domain:"www.example1.com" authz:<id:"1" identifier:"www.example1.com" registrationID:1 status:"valid" expires:1577840461000000001 > , Identifier:0xc0000b8060, RegistrationID:0xc0000b8070 domain:"www.example2.com" authz:<id:"2" identifier:"www.example2.com" registrationID:2 status:"valid" expires:1580608922000000002 > , Identifier:0xc0000b8100, RegistrationID:0xc0000b8110 domain:"www.example3.com" authz:<id:"3" identifier:"www.example3.com" registrationID:3 status:"valid" expires:1583204583000000003 > , Identifier:0xc0000b81a0, RegistrationID:0xc0000b81b0
無事、それぞれのドメインに応じた値になっています。
22行目のkCopy変数の処理コメントを見ると、iterator変数をloopする際に参照を使う問題についてちゃんと意識してコードを書いていたことがわかります。本当に惜しい。
レポートでは kCopy は問題を回避しているのに v について見逃したのは、protocol buffer ver2 におけるフィールド値の代入が全て参照渡しになっていることも一因にあると分析しています。そのためつい参照渡しにしてしまったのでしょう。
再発防止策として、テストやログの充実、静的解析やレビューの実施、protocol buffer ver3のアップグレードなどが挙げられています。
ハマるところをちゃんと理解して回避したつもりがホントちょっとの思い込みで他の手当を忘れてしまう、胸に手をあてて見ても過去そんなことがあった覚えがありますし、これからも絶対に自分に起こらないとは言えません。怖いことです。
今回のインシデントは対岸の火事とはとても思えません。自分もこういうインシデントを将来起こさないよう本当に気をつけたいとレポートを読んでしみじみ思うのでした。
Windows CryptoAPIの脆弱性によるECC証明書の偽造(CVE-2020-0601)
1. はじめに
つい先日のWindowsのセキュリティアップデートでWindowsのCryptoAPIの楕円曲線暗号処理に関連した脆弱性の修正が行われました。
「CVE-2020-0601 | Windows CryptoAPI Spoofing Vulnerability」
これがまぁ世界の暗号専門家を中心にセキュリティ業界を驚かせ、いろいろ騒がしています。
その驚きの一つは、この脆弱性の報告者がNSA(米国家安全保障局)だったことです。NSAはMicrosoftのアナウンスとは別により詳しい内容でこの脆弱性を警告するアナウンスを出しています。
「Patch Critical Cryptographic Vulnerability in Microsoft Windows Clients and Servers」
これまで数々の諜報活動をインターネット上で行ってきたNSAが、この脆弱性を自分たちの諜報活動に利用しないというのだろうか?
楕円曲線暗号にバックドアを仕込んだのではないかと疑われているNSAが、自ら発見した楕円曲線暗号処理の脆弱性をわざわざ開発元に報告し、修正を求めるなんてことが本当にありうるのだろうか?
他にも、NSAは既にもっと巧妙な攻撃方法を使っているのでもうこの脆弱性はいらなくなったとか、他国がこの脆弱性を狙った攻撃を使い始めたからとか、いろんなことを想像しちゃいます。
まぁこれが本当なら世の中かなり変わったものです。
こういった騒ぎの中で、Hacker Newsではこの脆弱性の原因について解説をするコメントが寄せられていました。
「CVE-2020-0601の攻撃方法について述べたHacker Newsのコメント」
これを読んでみると、この脆弱性なかなかヤバそうです。早速世界中でこの脆弱性をついて exploit するPoCが作成され、既にいくつか公表されています。
その中で Kudelski Security が公表した、
「CVE-2020-0601: THE CHAINOFFOOLS/CURVEBALL ATTACK EXPLAINED WITH POC」
の内容は非常に具体的です。私も試してみると本当にHTTPSサーバの証明書を偽造することができました。このデモは、時雨堂さんのサイトを偽造してします。Vさん、ごめんなさい。

スクリーンショットにあるよう、IE11のURL表示バーには何もエラーが出ていません。ただし証明書のパスのチェックしてみると、ルート証明書にバッテンがついています。なんか不思議な状態です。通常のユーザはこれが異常であることに気づかないでしょう。
ちなみにWindows Updateで脆弱性修正のパッチをあててみると、まずDefenderがブロックしてサイトにアクセスできません。警告を受け入れてアクセスしてみると、見事URLバーが赤色になり証明書エラーの表示が出ています。

これだとひと目で攻撃サイトにアクセスしていることがわかります。まだWindows Updateしていない皆さん、直ちにパッチをあてましょう。
今回は、この脆弱性のしくみと上記の試験で検証した Kudelski Security が公表したHTTPSサーバを偽造する攻撃手法に限定にして解説したいと思います。コード署名やVPNなどでは他の攻撃ベクターが存在している可能性があります。ご注意ください。
2. 超ざっくりしたECDSAの解説
今回の脆弱性は、ECDSA(Elliptic Curve Digital Signature Algorithm)の処理に関連したものです。 ここでECDSAのしっかりした解説をするのはかなり荷が重いです。なので、この記事が分かる程度に超ざっくりとECDSAがどういうものか書いてみます。
これでなんとなく雰囲気を掴んでいただければと思います。ただかなり雑に書いているので、正確に理解したいならちゃんとした本や資料で勉強してください。
楕円曲線暗号の特徴は、ECパラーメータという数値セットで決定されます。そのECパラメータには、曲線の係数やベースポイント(G)と呼ばれる計算の開始点、剰余算を行う素数の値、その他いくつかの数値が含まれます。もちろん楕円曲線暗号の種類によってその中身も変わります。
この楕円曲線上の点で、数学的に決まった形で剰余演算を行います。楕円曲線暗号方式のキモは、ある楕円曲線上の点Gを何倍かして新しい点の位置を計算することはできるが、逆にある点を見てGを何倍してたどり着いた点なのか、その倍数を見つけるのが非常に難しいという性質です。さらに楕円曲線上の点Gを2倍3倍…と進んでいくと、同じ点Gに戻ってくるという性質もあります。

ECDSAは、この楕円曲線暗号を使った署名方式です。
上図の様にG、P(公開鍵)を署名者、署名検証者の間で交換しておきます。署名者は、署名作成時に乱数rから生成される点Rとメッセージのハッシュ値(Hash(M))と合わせて署名値SとRのx座標(Rx)を計算し、メッセージと共に署名検証者に渡します。
署名検証者は、受け取った署名値(Rx, S)とメッセージM、あらかじめ知っているGとPを使って別にRを計算します。この計算したRのX座標が、受け取ったRxと一致していれば署名検証成功です。
Pを生成する秘密鍵dを知っている者でないと、この計算を一致させる署名値を作ることができないからです。
こういった特徴を持つECDSA署名のしくみによってメッセージの認証や完全性が保証され、なりすましや改ざんといった脅威から守ることが可能となります。
3. CVE-2020-0601の脆弱性
今回のWindowsの脆弱性 CVE-2020-0601 は、CryptoAPI のバグをついてECパラメータを偽造し、署名検証をバイパスできてしまう脆弱性です。
ベースポイントGを含むECパラメータは、通常セットで名前付けられており、P-256, P-384などの名前で呼んで識別します(namedCurve)。ただし同じECパラメータでも名付け団体によって名前が異なるのでややこしいし、混乱します。
仕様的には名前付けされたパラメータセットではなく、ベタでECパラメータを書いている方式も認められています(specifiedCurve)。
修正される以前のWindows CryptoAPIでは、このECパラメータの処理する際にベースポイントGをチェックする処理が見落とされるバグを持っていました。
通常署名で利用する公開鍵は、証明書に記載されています。公開鍵を変えてしまうと別の証明書であると見なされます。そこで攻撃者は、ベースポイントGのチェックが甘いCryptoAPIのバグをついて、Gを秘密鍵がわかる位置まで移動させてしまえば、公開鍵Pに対応した秘密鍵を攻撃者が自由に設定できることを見つけました。
秘密鍵がわかる位置、そうですG'を公開鍵Pの倍数の位置まで動かせばいいのです。
公開鍵Pの座標を変えられないから計算の起点であるベースポイントGを動かす、逆転の発想です。

署名検証者が利用するベースポイントGをなんらかの方法で変更することが可能であるならば、公開鍵の値はそのままで攻撃者が自由に秘密鍵の値を決めることができてしまうのです。なんてことでしょう。
署名検証者が利用するCryptoAPIではベースポイントのチェックが漏れています。何も知らずに偽造されたベースポイントG'を利用して署名検証をしてしまうと偽造署名の検証が通ってしまうことになります。
もう少し細かくこれを数式で示したのが以下の図です。

自分も実際に紙上で手計算するまでは信じられませんでしたが、お見事です。これ見つけた人はすごい。
当初 twitter で公開した図の計算式に関しては、 xagawa さん と super duper blooper さん から貴重なコメントを頂きました。深く感謝いたします。また頂いたコメントに従い一部表現を修正しました。
4. ECC証明書の形式
ではどうやって偽造したベースポイントG'を署名検証者に伝えるのでしょうか? 証明書を使えばいけそうです。
ECDSA署名で利用するECC証明書には、namedCurve形式とspecifiedCurve形式の2通りが存在します。仕様的には3つ目のimplictCurve形式も存在しますが、今回は対象外とします。
各形式の証明書を実際に見てみましょう。
4.1 namedCurve形式のECC証明書
namedCurve形式の証明書は以下の形です。証明書のなかほどに、ASN1 OID: prime256v1, NIST CURVE: P-256 と書いてあります。これがECパラメータを表す名前です。

この名前(prime256v1)で規定されているECパラメータの中身は、opensslのコマンドで以下の様に簡単に確認することができます。
$ openssl ecparam -name prime256v1 -text -param_enc explicit -noout
Field Type: prime-field
Prime:
00:ff:ff:ff:ff:00:00:00:01:00:00:00:00:00:00:
00:00:00:00:00:00:ff:ff:ff:ff:ff:ff:ff:ff:ff:
ff:ff:ff
A:
00:ff:ff:ff:ff:00:00:00:01:00:00:00:00:00:00:
00:00:00:00:00:00:ff:ff:ff:ff:ff:ff:ff:ff:ff:
ff:ff:fc
B:
5a:c6:35:d8:aa:3a:93:e7:b3:eb:bd:55:76:98:86:
bc:65:1d:06:b0:cc:53:b0:f6:3b:ce:3c:3e:27:d2:
60:4b
Generator (uncompressed):
04:6b:17:d1:f2:e1:2c:42:47:f8:bc:e6:e5:63:a4:
40:f2:77:03:7d:81:2d:eb:33:a0:f4:a1:39:45:d8:
98:c2:96:4f:e3:42:e2:fe:1a:7f:9b:8e:e7:eb:4a:
7c:0f:9e:16:2b:ce:33:57:6b:31:5e:ce:cb:b6:40:
68:37:bf:51:f5
Order:
00:ff:ff:ff:ff:00:00:00:00:ff:ff:ff:ff:ff:ff:
ff:ff:bc:e6:fa:ad:a7:17:9e:84:f3:b9:ca:c2:fc:
63:25:51
Cofactor: 1 (0x1)
Seed:
c4:9d:36:08:86:e7:04:93:6a:66:78:e1:13:9d:26:
b7:81:9f:7e:90
今回注目のベースポイントGは、Generator (uncompressed) の項目に該当します。uncompressedは、ベースポイントの座標がX,Yの座標でエンコードされていることを示しています。
namedCurve形式のECC証明書は、opensslのデフォルトでECC証明書の秘密鍵を生成すると使えます。
$ openssl ecparam -out namedCurvePrivate.key -name prime256v1 -genkey
後述しますが、インターネットのPKIシステムで使われる証明書はこのnamedCurve形式になります。
4.2 specifiedCurve形式のECC証明書
specifiedCurve形式のECC証明書は、ECパラメータを証明書内にベタに書き込む形式です。
以下の証明書は、先のnamedCurve形式と全く同じECパラメータ(P-256)の証明書です。しかし名前ではなくECパラーメータの値がベタに記載されています。
先程のopensslで出力したECパラメータと全く同じ値が証明書内に明示的に記載されていることがわかるでしょう。

今回のCVE-2020-0601は、ここに書かれているベースポイントを偽造した値に入れ替えた証明書を使い攻撃を行います。
specifiedCurve形式のECC証明書は、opensslでECC証明書の秘密鍵を生成する際に、-param_enc explicit を付けると使えます。
$ openssl ecparam -out specifiedCurvePrivate.key -name prime256v1 -genkey -param_enc explicit
5. Kudelski Security が実証した攻撃手法
では実際にKudelski Security が実証した攻撃手法を試してみます。
時雨堂ドメインのサーバ証明書を偽装し、IE11のブラウザーからエラーを出さずに偽のWebサーバにアクセスさせる攻撃です。
具体的な攻撃コードは、
にのっています。
5.1 偽造ベースポイントのルート証明書を作る
まずは適当な本物のルートECC証明書を探します。Kudelski Securityでは、現Sectigo社が管理するUSERTRUST NetworkのルートECC証明書を利用しました。

このルートECC証明書は、namedCurve形式でP-384を利用していることがわかります。
次に攻撃用のルート証明書を作成します。本物のルート証明書から、シリアルと公開鍵データをパクります。
次に、P-384のECパラメータを記載したspecifiedCurve形式の証明書から偽造ベースポイントを公開鍵を2倍にした座標に変更します。

G'=2Pなので秘密鍵は1/2となります。1/2といっても小数ではなく整数で表します。2倍して1になる数なので、1周して元に戻るちょうど中間折返し地点までの数を示します*1。
5.2 時雨堂の偽造サーバ証明書を作る
時雨堂になりすましを行うHTTPSサーバ用の証明書を作り、この偽造ルートECC証明書を使って署名します。subjectAltName に shiguredo.jp を入れ込んでいます。

5.2 Windows CryptoAPIのキャッシュを上書き
脆弱性をついて攻撃できるルート証明書を作成できたとしても、どうやってこれをターゲットの端末に認識させられるのでしょうか? ルート証明書は通常端末の中で管理されており、外部の攻撃者がルート証明書を入れ替えたりすることは容易ではありません。
ここでもう一つの Windows CryptoAPI のバグ(仕様?)をつきます。
どうもCryptoAPIは、署名検証で利用した証明書をキャッシュしているようです。
ここからはWindows内部の挙動になるので想定になりますが、どうもシリアル番号・公開鍵・Subjectの情報など証明書の一部の情報が一致していると、ルート証明書といえどもキャッシュ更新を行う感じです。
2020年1月22日追記: McAfeeから調査ブログが出てました。思ったよりひどそう。 blogs.mcafee.jp
まず最初に攻撃対象となっている本物のルート証明書から発行されたサイトにアクセスしてルート証明書のキャッシュを作成させます。
次に攻撃者は、偽造ルート証明書と偽造サーバ証明書をクライアントに送り込みます。通常はルート証明書をサーバからクライアントに送ることはありませんが、しったこっちゃありません。
これを受け取ったクライアントのCrypto APIでは、なんと偽造ルート証明書にキャッシュを更新します。
本来ならECパラメータなど完全に同一のものか厳密にチェックしないといけないのですが、なんとベースポイントのチェックを忘れるバグがありました。楕円曲線の係数とかの情報はちゃんとチェックしているようで完全な見落としだと思います。
偽造ルート証明書は、CryptoAPI内では正常なルート証明書として扱われ偽造サーバ証明書の署名検証が成功することになります。これで最初に示した攻撃が完了です。
 最初に示した攻撃に成功した画面では証明書パスのチェックでルート証明書にバッテンがついていました。これはキャッシュ上のルート証明書で署名検証は成功しているけどクライアントで管理している本当のルート証明書でないのでバッテンをつけているのだと思われます。
最初に示した攻撃に成功した画面では証明書パスのチェックでルート証明書にバッテンがついていました。これはキャッシュ上のルート証明書で署名検証は成功しているけどクライアントで管理している本当のルート証明書でないのでバッテンをつけているのだと思われます。
証明書パスがエラーならURLバーの表示でもエラーを出してもらいたいものです。
6. WindowsはRFC5480違反?
実はインターネットのPKIシステムでspecifiedCurve形式の証明書を利用することはRFC違反なんです。 https://tools.ietf.org/html/rfc5480#section-2.1.1 では明確に、
implicitCurve and specifiedCurve MUST NOT be used in PKIX. (implicitCurveとspecifiedCurveはPKIXでは利用しては**いけない**。)
規定されています。おそらく企業ユーザなどで過去TLS1.0/1.1の古い時代にspecifiedCurve形式を使った証明書を扱うようなケースがあり、互換性を維持するためにこうなってしまったのではないかと思われますが、本当のことはわかりません。
OpenSSLでも以下の issue でspecifiedCurve形式のクライアント証明書が使えなくなったというissueがあがってました。
Connection error when using EC client certificate with explicit parameters and TLS1.2
結局RFC5480に従うということでWon't Fix扱いでクローズされました。実際にspecifiedCurve形式のサーバ証明書を受け取るとopenssl-1.1.1のクライアントはエラーで接続できないです。
どういう理由かはわかりませんが、RFC違反で残っていた機能がこんなところで大きな脆弱性として出てきてしまったことは皮肉なもんです。
歴史の長いIEだからこそ起きてしまっことなのかも知れません。新しいMicrosoft EDGEでは、ChromiumのネットワークスタックやTLSライブラリ(BoringSSL)を利用しているようなので同じようなことを心配しなくても良くなるでしょう。
Google Chromeについて(2020年1月20日追記)
IE11は脆弱性の影響を受け、Google Chromeや新しいMicrosoft EDGEでは問題ないように捉えられる記述をしていましたが、間違いでした。
Chrome も Windows CryptoAPIの CertGetCertificateChain を利用しており、下記コードで修正が入っています(修正版のChrome 79がリリース済み)
41853ce2057201bdd225aee96be4e6cd51b2458b - chromium/src.git - Git at Google
ただし、Google Chromeの場合はサーバ証明書に Certificate Transparency (SCT)が入っていないといけないので、SCT必須となる以前の2018年5月1日以前に発行された証明書に偽造する必要があります。
*1:実際には P-384 の order を法として2の逆数を求めます
なぜChromeはURLを殺そうとするのか? (Chrome Dev Summit 2019)
今年もChrome開発者の集まりChrome Dev Summit 2019 (CDS) がサンフランシスコで開催されました。 今回、私が Chrome Customer Advisory Board (CAB) に選出していただいたこともあり、CDSに初めて参加しました。
これは、CDS終了後のCAB meetingで頂いたChrome Dinosaurフィギュアです。ちなみにゲームはできません。
 タイトルの「なぜChromeはURLを殺そうとするのか?」は、2日目Chrome Leadsのパネルセッションで司会のGooglerが、Chrome UX担当のProduct Managerに対して一番最初に投げかけた問いです。
タイトルの「なぜChromeはURLを殺そうとするのか?」は、2日目Chrome Leadsのパネルセッションで司会のGooglerが、Chrome UX担当のProduct Managerに対して一番最初に投げかけた問いです。
PMは直ちに「そんなことはしない」と即答しました。しかしChromeは、URLの表示領域からHTTPSの緑色表示の廃止・EV表示場所の移動・wwwサブドメイン表示の削除、といったセキュリティに関連するUI変更を立て続けに行ってきています。
Googleは、URLをどう考えていて、ChromeのUIを将来どうしていくのか?
その方向性は1日目のセッション「Protecting users on a thriving web (繁栄しているウェブの上でユーザを守る)」で話されています。
Protecting users on a thriving web (Chrome Dev Summit 2019)
世界的にHTTPS Everywhereが普及し、HTTPS化されたフィッシングサイトも増大している中、今後のChromeブラウザにおけるURL表示に対する考え方は、従来と大きく変わることになりそうです。 今回そのセッションの内容について紹介したいと思います。
このセッションは、2つに別れています。前半は、Chromeのセキュリテイ担当エンジニア Emily Stark さんによるChromeのURL表示に関するセッションです。以下は、おおよその講演内容を文字に起こしたものです。
1. あなたはウェブのどこにいるのか? サイトのアイデンティティをわかりやすくする。
ウェブブラウザの上部に表示されるURLは、ウェブサイトのアイデンティティに対する曖昧な手がかりでしかありません。
ドメイン名からサイトのアイデンティティを特定することは、簡単なことではありません。セキュリティ専門家でも見分けがつかないこともあるし、非技術者のユーザとってなおさら無理な話です。
このことは憶測に基づくものではなく、多くの実験や調査で示されています。セキュリティに対してちゃんとした決定をしなければならない時に、多くのユーザはURLに気づかなかったり、URLを理解できていないのです。
Googleは、1000人以上を対象とした調査を行いました。対象ユーザにGoogleのログインページにみえるブラウザウィンドウを見せると、アドレスが明確に tinyurl.com になっていても、85%の人がそのウェブサイトをGoogleだと言うことがわかりました。
 これは本当に非常に難しい問題です。
これは本当に非常に難しい問題です。
多くの人々は、本当に便利なものとしてURLを利用しています。しかし、URLが人々を騙したり、害を及ぼすことに使われたりすることもよくあります。
そのためGoogleは、いくつかの方向からこの問題にアプローチしています。それは、
- URLを悪用する巧妙なスプーフィング技術に対して、積極的に対策をします。
- セキュリティを決定づける最も重要なURL情報に、人々の注意を向けるようにします。
- 専門家をサポートする特別なツールを作っています。それをURLをより良くするセキュリテイツールとして役立たせます。
というアプローチです。

1.1. スプーフィング対策
IDNを使った spoofing は見分けがつかないです。example.comのaがキリル文字だったとしてもわかりません。
 Chrome75から「Look-alike Warning」という新しい警告を入れるようにしました。これはスプーフされたIDNを検知し、攻撃されていると思われる場合ユーザを正式なサイトに導くページを表示します。
Chrome75から「Look-alike Warning」という新しい警告を入れるようにしました。これはスプーフされたIDNを検知し、攻撃されていると思われる場合ユーザを正式なサイトに導くページを表示します。
 Chromeがナビゲーション中のドメインにIDNを見つけると、同じように見える文字種を一つにまとめるアルゴリズムを使い、ドメイン名をスケルトンに変換します。
そしてそれを有名なサイトや過去にユーザが訪れたサイトのスケルトンと比較します。もし合致すれば、ユーザを正しいサイトに導くよう、この警告を表示します。
Chromeがナビゲーション中のドメインにIDNを見つけると、同じように見える文字種を一つにまとめるアルゴリズムを使い、ドメイン名をスケルトンに変換します。
そしてそれを有名なサイトや過去にユーザが訪れたサイトのスケルトンと比較します。もし合致すれば、ユーザを正しいサイトに導くよう、この警告を表示します。

1.2. セキュリティに関連したものを強調する
1.2.1. EV表示の廃止
Chrome77より、EV証明書の表示をPage Infoに移す変更をしました。これまでの調査・研究結果から、EV証明書が人々にサイトのアイデンティティを理解させるのに役立っていないことがわかったからです。
(以下省略: これについては直前のエントリー「Google Chrome EV表示の終焉」に詳しく書きましたので、そちらを参照してください。 )
1.2.2. OmniboxにおけるURL表示の簡略化
HTTPS以外では警告を出すようにしたため、Onmiboxで scheme (https://) を非表示にしました。
大多数の人にとって、wwwサブドメインの表示をしてもしなくても違いはありません。多くのユーザには、それは visual noise となるし、セキュリティに関連した部分をURLで見つけるのが難しくなります。ユーザに対しては、多くの情報を与えないようにします。
UIをより簡単にして、ユーザの注意をURLのセキュリティに関連した部分(ドメイン名)にフォーカスさせます。そのため、これらのURLコンポーネントを隠しました。これを「steady state Omnibox」と呼んでいます。

1.2.3. 将来的な変更について (鍵アイコンの削除など)
将来的には、もっとドメイン名に注意を引きつけるUI変更も考えています。
- OmniboxでURLを編集しようとクリックするまでパスを隠すべきか?
- ドメイン名を太字にしたり大きく見せて、もっと際立たせるべきか?
- ユーザーが自分でドメインを検査することになった時に、パスをアニメーション化すべきか?
まだどれが良いのかわかっていません。
この考えに沿って、最終的にHTTPS接続を示す鍵アイコンも削除する予定です。
HTTPS接続を中立な状態として、デフォルトにします。そしてセキュリティがなくなった場合にのみ、警告を出すようにします。
鍵アイコンのような positive なインディケータは、かえってユーザを混乱させ、誤ったメッセージを送ることもあります。
(これはHTTPSのメンタルモデルを調査した論文を引用し、「鍵アイコンは、自分の認証が必要なことを指していると思っている」というユーザがいたことを指しています。)
 何も出なかったら安全なHTTPS接続である、と思ってもらえるようにしたいです。 Chromeは安全でなかったら、警告を出すようにします。
何も出なかったら安全なHTTPS接続である、と思ってもらえるようにしたいです。 Chromeは安全でなかったら、警告を出すようにします。
調査・準備にもっと時間が必要なので、鍵アイコンをいつ削除するのかは未定です。
1.3. 専門家向けのユーザケース
全員がURLを簡略化してほしいと望んでいません。ここへの最初の取り組みは、Suspicious Site Reporter というChrome拡張です。
この拡張を使うとOmniboxのURLが編集されず、常に完全に見えます。デフォルトで有効になっている非技術ユーザを助ける目的のURL簡略化を回避します。
 この拡張を使うと、悪意のあるサイトをGoogle Safe Browsing サービスに簡単に報告できます。Google Safe Browsingサービスは、 malicious活動をスキャンしているサービスです。
この拡張を使うと、悪意のあるサイトをGoogle Safe Browsing サービスに簡単に報告できます。Google Safe Browsingサービスは、 malicious活動をスキャンしているサービスです。
Safe Browsingサービスが、報告されたサイトがフィッシングやマルウェア配布・ソーシャルエンジニアリングなど、Googleポリシー違反をしていると判定すれば、全てのChromeユーザに対してそのサイトの訪問をブロックします。
2. ウェブはあなたの何を知るのか? 反映するウェブエコシステムのためのプライバシー確保API
後半は、Michael Kleberさんによる最近のウェブプライバシー関連の状況とChromeの取り組みについてです。本エントリーの内容から少し外れてしまうので解説は省略しますが、1つ重要なことだけ挙げておきます。
2020年2月リリース予定の Chrome 80 から、クッキーのデフォルト挙動が変わります。3rd party cookieは、今のままでは動作しなくなる可能性があります。影響を受けそうなサイトは、Googleからのアナウンス「新しい Cookie 設定 SameSite=None; Secure の準備を始めましょう」をよく読んで準備しましょう。

3. まとめ
以上セッションの内容から、Googleがスプーフィング対策・非技術者向けにURLの簡略化と効果的なUIの模索・専門家向けにURLを生で見せるChrome拡張の提供、の3つの柱でChromeのセキュリティ対策を進めているのがわかりました。
「これは実質的にURLを殺しにきているのではないか?」と言われれば、まぁそうなのかもしれません。
URL表示の簡略化は、Omniboxを使うとカーソルが微妙にずれてしまったりして個人的にも違和感があります。慣れの問題かなと半分諦めていました。今回 Suspicious Site Reporter を知って速攻で入れました。まぁホント快適です(フィッシングサイトの報告はまだしたことないです)。簡略URL表示に違和感のある方は、慣れる前に試してみることをお勧めします。これを使えば、今のところURLが殺されていない世界をGoogleから提供してもらえそうです。
ただHTTPS接続が当たり前となり、フィッシングが巧妙になり、非技術者ユーザが圧倒的多数を占める状況では、URLを確認しろ・証明書を確認しろ・リンクやサイトの記述に注意せよ、といった対応はそろそろ限界に来ているのかなとも思ったりします。
今回のセッションで紹介されたHTTPSメンタルモデルの論文「“If HTTPS Were Secure, I Wouldn’t Need 2FA”- End User and Administrator Mental Models of HTTPS」で報告されているユーザ調査には、少しショックを受けました。
“I think the lock symbol means that I have to authenticate myself. As I frequently forget my passwords, I usually try to click around to get rid of this symbol.” 「鍵アイコンは、自分の認証が必要なことを指していると思っている。 私はよくパスワードを忘れるので、この鍵アイコンを消すためにいつもいろんなところをクリックしてます。」
“HTTPS is a bad protocol. If HTTPS were secure, I wouldn’t need 2FA.” 「HTTPSは悪いプロトコルだ。もしHTTPSが安全なら私に2FAは必要ないだろう。」
まぁこういう状況なら、ChromeのURL表示が簡略化され、セキュリティアクション選択の多くがGoogleのお任せになるのも仕方ないかもしれません。
ところで、もらった Chrome Dinosaurフィギュアの箱を見てみると見慣れないURLが、
 試してみると、
試してみると、
 おぉ、 ERR_INTERNET_DISCONNECTED (-106) だったのか!
おぉ、 ERR_INTERNET_DISCONNECTED (-106) だったのか!